Künstliche Intelligenz ist wie jede transformative Technologie ein fortlaufender Prozess, wobei ihre Fähigkeiten und gesellschaftlichen Auswirkungen kontinuierlich zunehmen. Initiativen für vertrauenswürdige KI erkennen die realen Auswirkungen, die KI auf Menschen und die Gesellschaft haben kann, und zielen darauf ab, diese Macht auf verantwortungsvolle Weise für positive Veränderungen zu nutzen.
Was ist vertrauenswürdige KI?
Vertrauenswürdige KI ist ein Ansatz für die Entwicklung von KI, der für die Menschen, die damit interagieren, Sicherheit und Transparenz schafft. Entwickler vertrauenswürdiger KI wissen, dass kein Modell perfekt ist, und ergreifen Maßnahmen, um Kunden und der Allgemeinheit verständlich zu machen, wie die Technologie entwickelt wurde, welche beabsichtigten Anwendungsfälle es gibt und welche Begrenzungen sie aufweist.
Neben der Einhaltung von Gesetzen zum Datenschutz und Verbraucherschutz werden vertrauenswürdige KI-Modelle auf ihre Sicherheit und die Verringerung unerwünschter Biases getestet. Außerdem sind sie transparent und stellen Informationen wie Genauigkeitsbenchmarks oder eine Beschreibung der Trainingsdatenmenge für verschiedene Zielgruppen zur Verfügung, darunter für Aufsichtsbehörden, Entwickler und Verbraucher.
Prinzipien vertrauenswürdiger KI
Prinzipien vertrauenswürdiger KI stellen die Grundlage für die End-to-End-Entwicklung von KI bei NVIDIA dar. Sie verfolgen ein einfaches Ziel: Vertrauen und Transparenz in KI zu schaffen und die Arbeit von Partnern, Kunden und Entwicklern zu unterstützen.
Datenschutz: Einhaltung von Vorschriften und Sicherheit von Daten
KI wird oft als datenhungrig beschrieben. Mit je mehr Daten ein Algorithmus trainiert wird, desto genauer sind meist seine Vorhersagen.
Daten müssen aber irgendwo her kommen. Für die Entwicklung vertrauenswürdiger KI ist es von entscheidender Bedeutung, nicht nur zu berücksichtigen, welche Daten legal zur Verfügung stehen, sondern auch, welche Daten sozial verantwortungsvoll genutzt werden dürfen.
Entwickler von KI-Modellen, die auf Daten wie dem Bild, der Stimme, dem künstlerischen Werk oder Gesundheitsakten einer Person beruhen, sollten bewerten, ob Einzelpersonen einer Verwendung ihrer personenbezogenen Daten zugestimmt haben.
Für Institutionen wie Krankenhäuser und Banken bedeutet die Entwicklung von KI-Modellen, die Verantwortung für die Geheimhaltung von Patienten- oder Kundendaten und das Trainieren eines robusten Algorithmus miteinander in Einklang zu bringen. NVIDIA hat Technologie entwickelt, die föderiertes Lernen ermöglicht, wobei Forscher KI-Modelle entwickeln, die mit Daten verschiedener Institutionen trainiert werden, ohne dass vertrauliche Daten private Server eines Unternehmens verlassen.
NVIDIA DGX-Systeme und NVIDIA FLARE-Software haben mehrere föderierte Lernprojekte im Gesundheitswesen und im Finanzdienstleistungssektor unterstützt und für eine sichere Zusammenarbeit verschiedener Datenanbieter an präziseren, generalisierbaren KI-Modellen für medizinische Bildanalyse und Betrugserkennung gesorgt.
Sicherheit: Vermeidung unbeabsichtigter Schäden und böswilliger Bedrohungen
Sobald KI-Systeme bereitgestellt sind, haben sie reale Auswirkungen. Darum ist es unerlässlich, dass sie wie beabsichtigt funktionieren, um die Sicherheit von Benutzern sicherzustellen.
Die Freiheit, öffentlich verfügbare KI-Algorithmen zu nutzen, schafft immense Möglichkeiten für nützliche Anwendungen, bedeutet aber auch, dass die Technik für unbeabsichtigte Zwecke verwendet werden kann.
Zur Minimierung von Risiken hält NVIDIA NeMo Guardrails KI-Sprachmodelle auf der richtigen Spur, indem es Entwicklern in Unternehmen erlaubt, Grenzen für ihre Anwendungen festzulegen. Thematische Guardrails stellen sicher, dass Chatbots sich an bestimmte Themen halten. Sicherheits-Guardrails setzen Grenzen für die Sprache und Datenquellen, die Apps in ihren Antworten verwenden. Sicherheits-Guardrails sollen eine böswillige Nutzung großer Sprachmodelle, die mit Anwendungen von Drittanbietern oder Programmierschnittstellen (APIs) verbunden sind, verhindern.
NVIDIA Research arbeitet mit dem von DARPA geleiteten SemaFor-Programm zusammen, um Experten für digitale Forensik bei der Identifizierung von KI-generierten Bildern zu unterstützen. Letztes Jahr haben Forscher eine neuartige Methode zur Bekämpfung sozialer Vorurteile beim Einsatz von ChatGPT veröffentlicht. Außerdem entwickeln sie Methoden für Avatar-Fingerabdrücke, um zu erkennen, ob jemand das KI-animierte Abbild einer anderen Person ohne deren Zustimmung verwendet.
Um Daten und KI-Anwendungen vor Sicherheitsbedrohungen zu schützen, verfügen NVIDIA H100– und H200 Tensor Core-GPUs über Confidential Computing, das sicherstellt, dass vertrauliche Daten bei der Nutzung geschützt bleiben, unabhängig davon, ob sie vor Ort, in der Cloud oder am Edge bereitgestellt werden. NVIDIA Confidential Computing verwendet hardwarebasierte Sicherheitsmethoden, um dafür zu sorgen, dass unbefugte Personen Daten oder Anwendungen während der Ausführung weder anzeigen noch ändern können. Das ist normalerweise ein Zeitpunkt, zu dem Daten anfällig sind.
Transparenz: KI erklärbar machen
Für ein vertrauenswürdiges KI-Modell darf der Algorithmus keine Blackbox sein. Seine Entwickler, Benutzer und Stakeholder müssen in der Lage sein, zu verstehen, wie die KI funktioniert, um den Ergebnissen vertrauen zu können.
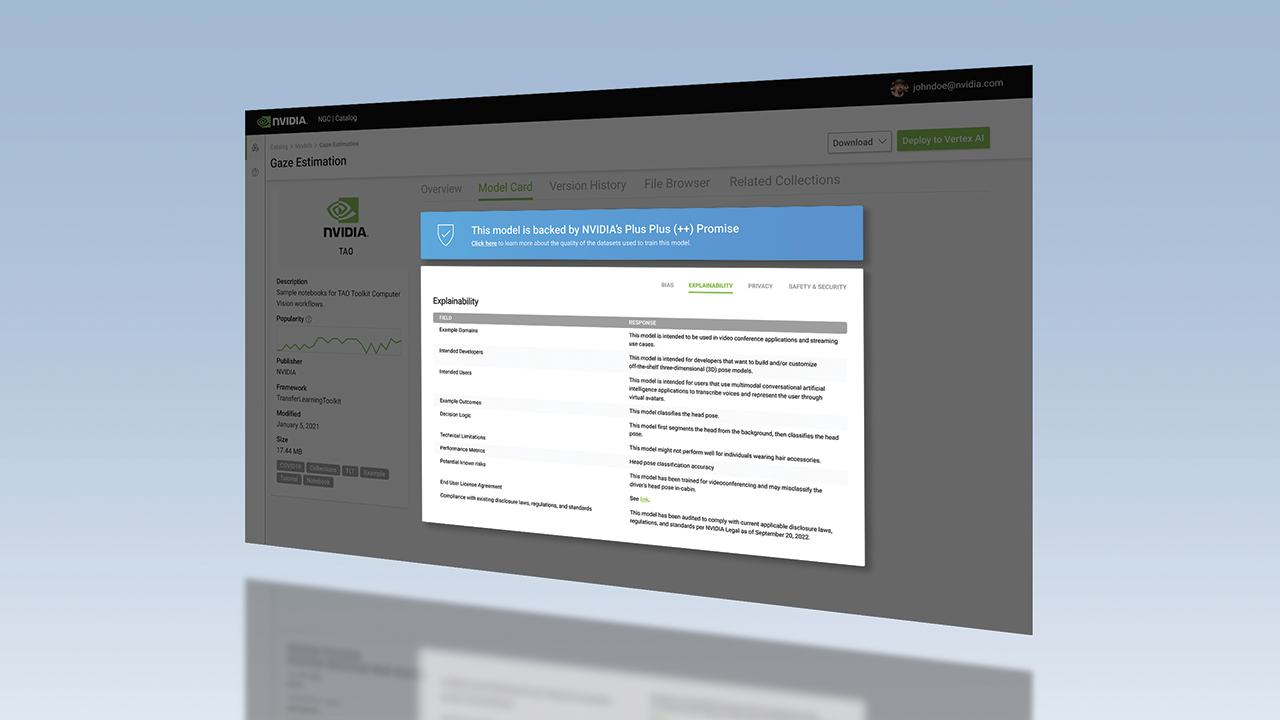
Transparenz in KI umfasst verschiedene bewährte Verfahren, Tools und Designprinzipien, die Benutzern und anderen Stakeholdern verständlich machen, wie ein KI-Modell trainiert wurde und wie es funktioniert. Erklärbare KI (Explainable AI, XAI) ist eine Untergruppe von Transparenz-Tools, die Stakeholder darüber informieren, wie ein KI-Modell bestimmte Vorhersagen und Entscheidungen trifft.
Transparenz und XAI sind entscheidend, um Vertrauen in KI-Systeme zu schaffen. Es gibt jedoch keine universelle Lösung, die für alle Arten von KI-Modellen und Stakeholdern geeignet ist. Die Suche nach der richtigen Lösung erfordert einen systematischen Ansatz, um zu ermitteln, wer von der KI betroffen sein wird, die damit verbundenen Risiken zu analysieren und effektive Mechanismen zur Bereitstellung von Informationen über das KI-System zu implementieren.
Retrieval-Augmented Generation (RAG) ist ein Verfahren, das die Transparenz von KI verbessert, indem generative KI-Dienste mit autoritativen externen Datenbanken verknüpft werden, sodass Modelle ihre Quellen angeben und genauere Antworten liefern können. NVIDIA unterstützt Entwickler mit einem RAG-Workflow, der das NVIDIA NeMo-Framework zur Entwicklung und Anpassung generativer KI-Modelle nutzt, bei den ersten Schritten.
Zudem ist NVIDIA Mitglied des U.S. Artificial Intelligence Safety Institute Consortium (AISIC) des National Institute of Standards and Technology (NIST), um dazu beizutragen, Tools und Standards für eine verantwortungsvolle Entwicklung und Bereitstellung von KI zu gestalten. Als Mitglied des Konsortiums fördert NVIDIA vertrauenswürdige KI, indem es bewährte Verfahren für die Implementierung von transparenten KI-Modellen nutzt.
Außerdem bietet NGC, der Hub von NVIDIA für beschleunigte Software, Modellkarten mit detaillierten Informationen dazu, wie einzelne KI-Modelle funktionieren und wie sie erstellt wurden. Das Format Model Card ++ von NVIDIA beschreibt die verwendeten Datenmengen, Trainingsmethoden und Leistungsmetriken, Lizenzinformationen sowie spezifische ethische Aspekte.
Nichtdiskriminierung: Minimierung von Biases
KI-Modelle werden von Menschen trainiert, wobei häufig Daten zum Einsatz kommen, die in Bezug auf Größe, Umfang und Vielfalt begrenzt sind. Um sicherzustellen, dass alle Menschen und Communitys die Möglichkeit haben, von dieser Technologie zu profitieren, ist es wichtig, unerwünschte Biases in KI-Systemen zu reduzieren.
Neben der Einhaltung von staatlichen Vorschriften und Antidiskriminierungsgesetzen mindern Entwickler von vertrauenswürdiger KI potenzielle unerwünschte Biases, indem sie nach Hinweisen und Mustern suchen, die darauf hindeuten, dass ein Algorithmus diskriminierend ist oder bestimmte Merkmale unangemessen verwendet. Bekannt sind rassistische und geschlechtsspezifische Vorurteile in Daten, aber andere Aspekte umfassen kulturelle Vorurteile sowie Vorurteile, die bei der Datenkennzeichnung eingeführt werden. Um unerwünschte Biases zu verringern, können Entwickler verschiedene Variablen in ihre Modelle integrieren.
Synthetische Datenmengen stellen eine Möglichkeit dar, um unerwünschte Biases in Trainingsdaten zu reduzieren. Sie werden zur Entwicklung von KI für autonome Fahrzeuge und Robotik verwendet. Wenn Daten, die zum Trainieren von selbstfahrenden Autos verwendet werden, ungewöhnliche Szenen wie extreme Wetterbedingungen oder Verkehrsunfälle nicht ausreichend darstellen, können synthetische Daten dazu beitragen, die Vielfalt der Datenmengen zu erhöhen, um die reale Welt besser zu repräsentieren und die Genauigkeit von KI zu erhöhen.
NVIDIA Omniverse Replicator ist ein Framework, das auf der NVIDIA Omniverse-Plattform zur Erstellung und Verwendung von 3D-Pipelines und virtuellen Welten aufbaut. Es hilft Entwicklern dabei, eigene Pipelines für die Generierung synthetischer Daten einzurichten. Und durch Integration des NVIDIA TAO Toolkits für Transferlernen mit Innotescus, einer Webplattform für die Kuratierung unvoreingenommener Datenmengen für Computer Vision, können Entwickler Muster und Biases von Datenmengen besser verstehen und so statistische Ungleichgewichte beheben.
Erfahren Sie mehr über vertrauenswürdige KI unter NVIDIA.com oder im NVIDIA-Blog.