
Anmerkung der Redaktion: Dieser Artikel wurde ursprünglich am 15. November 2023 veröffentlicht und in der Zwischenzeit überarbeitet.
Um die neuesten Fortschritte im Bereich der generativen KI zu verstehen, stellen Sie sich einen Gerichtssaal vor.
Richter verhandeln und entscheiden Fälle auf der Grundlage ihres allgemeinen Rechtsverständnisses. Manchmal erfordert ein Fall – wie ein Kunstfehler oder ein Arbeitskonflikt – besonderes Fachwissen. Deshalb schicken Richter Gerichtsangestellte in eine Rechtsbibliothek, um nach Präzedenzfällen und spezifischen Fällen zu suchen, die sie zitieren können.
Wie ein guter Richter können große Sprachmodelle (LLMs) auf eine Vielzahl von menschlichen Abfragen antworten. Um jedoch maßgebliche Antworten liefern zu können, die Quellen zitieren, benötigt das Modell einen Assistenten, der Recherchen vornimmt.
Der Gerichtsbedienstete bei KI ist ein Prozess, der als Retrieval-Augmented Generation (RAG) bezeichnet wird.
Wie der Prozess den Namen „RAG“ (Englisch für „Lumpen“) erhalten hat
Patrick Lewis, Hauptautor einer Studie aus dem Jahr 2020, die den Ausdruck geprägt hat, entschuldigte sich für das wenig schmeichelhafte Akronym, das heute eine wachsende Zahl von Methoden in Hunderten von Artikeln und Dutzenden von kommerziellen Diensten beschreibt, die seiner Meinung nach die Zukunft der generativen KI prägen werden.
 Patrick Lewis: „Wir hätten uns definitiv mehr Gedanken über den Namen gemacht, wenn wir gewusst hätten, dass unsere Arbeit so große Verbreitung finden würde“, sagte Lewis bei einem Interview in Singapur, bei dem er seine Ideen im Rahmen einer regionalen Konferenz mit Datenbankentwicklern teilte.
Patrick Lewis: „Wir hätten uns definitiv mehr Gedanken über den Namen gemacht, wenn wir gewusst hätten, dass unsere Arbeit so große Verbreitung finden würde“, sagte Lewis bei einem Interview in Singapur, bei dem er seine Ideen im Rahmen einer regionalen Konferenz mit Datenbankentwicklern teilte.
„Wir hatten immer geplant, einen schöneren Namen zu finden, aber als es an der Zeit war, den Artikel zu schreiben, hatte niemand eine bessere Idee“, erklärte Lewis, der inzwischen ein RAG-Team beim KI-Startup Cohere leitet.
Was also ist Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) ist ein Verfahren zur Verbesserung der Genauigkeit und Zuverlässigkeit von generativen KI-Modellen mithilfe von Fakten, die aus externen Quellen abgerufen werden.
Anders ausgedrückt: RAG schließt eine Lücke in der Funktionsweise von LLMs. Unter der Haube von LLMs befinden sich neuronale Netze, die in der Regel daran gemessen werden, wie viele Parameter sie enthalten. Die Parameter eines LLMs repräsentieren im Grunde die allgemeinen Muster, wie Menschen Wörter zur Bildung von Sätzen verwenden.
Dieses tiefgreifende Verständnis, das manchmal als parametrisiertes Wissen bezeichnet wird, macht LLMs nützlich bei der extrem schnellen Beantwortung allgemeiner Aufforderungen. Sie eignen sich jedoch nicht für Benutzer, die tiefer in eine aktuelle oder spezifischere Materie eintauchen möchten.
Kombination von internen und externen Ressourcen
Lewis und seine Kollegen entwickelten Retrieval-Augmented Generation, um generative KI-Dienste mit externen Ressourcen zu verknüpfen, insbesondere solchen, die über neueste technische Daten verfügen.
Das Forschungspapier, an dem Co-Autoren vom früheren Facebook AI Research (jetzt Meta AI), des University College London und der New York University beteiligt waren, bezeichnete RAG als „universelles Feinabstimmungsrezept“, da es von nahezu jedem LLM verwendet werden kann, um eine Verknüpfung zu praktisch beliebigen externen Ressourcen herzustellen.
Schaffung von Benutzervertrauen
Retrieval-Augmented Generation stellt Modellen Quellen zur Verfügung, die sie zitieren können (wie Fußnoten in einer Forschungsarbeit), damit Benutzer Behauptungen überprüfen können. Das schafft Vertrauen.
Darüber hinaus kann das Verfahren Modellen dabei helfen, Mehrdeutigkeiten in Benutzerabfragen zu klären. Außerdem verringert es die Wahrscheinlichkeit, dass ein Modell falsche Vermutungen trifft, ein Phänomen, das manchmal auch als Halluzination bezeichnet wird.
Ein weiterer großer Vorteil von RAG ist, dass das Verfahren relativ simpel ist. In einem Blogbeitrag von Lewis und drei der Co-Autoren des Forschungspapiers wurde beschrieben, dass Entwickler den Prozess mit nur fünf Codezeilen implementieren können.
Das macht die Methode schneller und kostengünstiger als das Neutrainieren eines Modells mit zusätzlichen Datenmengen. Außerdem können Benutzer neue Quellen im laufenden Betrieb hinzufügen.
Wie Menschen RAG nutzen
Mit Retrieval-Augmented Generation können Benutzer im Wesentlichen Konversationen mit Daten-Repositorys führen, was neue Arten von Erlebnissen möglich macht. Das bedeutet, dass die Anwendungen für RAG ein Vielfaches der Anzahl der verfügbaren Datenmengen ausmachen könnten.
Beispielsweise könnte ein generatives KI-Modell, das um einen medizinischen Index ergänzt wird, ein toller Assistent für einen Arzt oder einen Krankenpfleger sein. Finanzanalysten würden von einem Assistenten profitieren, der mit Marktdaten verknüpft ist.
Im Prinzip kann fast jedes Unternehmen seine technischen oder Richtlinien-Handbücher, Videos oder Protokolle in Ressourcen umwandeln, die als Wissensdatenbanken bezeichnet werden und LLMs optimieren können. Solche Quellen können Anwendungsmöglichkeiten wie Kunden- oder Außendienstsupport, Mitarbeiterschulungen und Entwicklerproduktivität unterstützen.
Das umfangreiche Potenzial ist der Grund, warum Unternehmen wie AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle und Pinecone RAG nutzen.
Erste Schritte mit Retrieval-Augmented Generation
Um Benutzern den Einstieg zu erleichtern, hat NVIDIA einen KI-Blueprint für die Einrichtung virtueller Assistenten entwickelt. Unternehmen können diese Referenzarchitektur nutzen, um Abläufe beim Kundenservice mit generativer KI und RAG schnell zu skalieren oder mit der Entwicklung einer neuen kundenorientierten Lösung zu beginnen.
Der Blueprint verwendet einige der neuesten Methoden zur Entwicklung von KI sowie NVIDIA NeMo Retriever, eine Sammlung von benutzerfreundlichen NVIDIA NIM-Microservices für das Abrufen von Daten in großem Maßstab. NIM erleichtert die Bereitstellung einer sicheren, leistungsstarken KI-Modellinferenz in Clouds, Rechenzentren und Workstations.
Diese Komponenten sind allesamt Teil von NVIDIA AI Enterprise, einer Softwareplattform, die die Entwicklung und Bereitstellung produktionsfähiger KI beschleunigt und dabei die Sicherheit, den Support und die Stabilität bietet, die Unternehmen benötigen.
Außerdem gibt es ein kostenloses NVIDIA LaunchPad Lab für die Entwicklung von KI-Chatbots mit RAG, damit Entwickler und IT-Teams auf der Grundlage von Unternehmensdaten schnell und präzise Antworten generieren können.
Für maximale Leistung von RAG-Workflows sind enorme Mengen an Arbeitsspeicher und Rechenleistung für das Bewegen und Verarbeiten von Daten erforderlich. Der NVIDIA GH200 Grace Hopper Superchip mit seinen 288 GB an schnellem HBM3e-Arbeitsspeicher und 8 Petaflops Rechenleistung ist ideal für RAG, da er eine 150-fache Beschleunigung gegenüber dem Einsatz einer CPU ermöglichen kann.
Sobald Unternehmen mit RAG vertraut sind, können sie eine Vielzahl von sofort einsatzbereiten oder eigens entwickelten LLMs mit internen oder externen Wissensdatenbanken kombinieren, um ein breites Spektrum von Assistenten zu erstellen, die Mitarbeitern und Kunden weiterhelfen.
RAG erfordert kein Rechenzentrum. LLMs lassen sich auch auf Windows-PCs einsetzen dank NVIDIA-Software, die es Benutzern ermöglicht, sogar über ihre Laptops auf alle Arten von Anwendungen zuzugreifen.
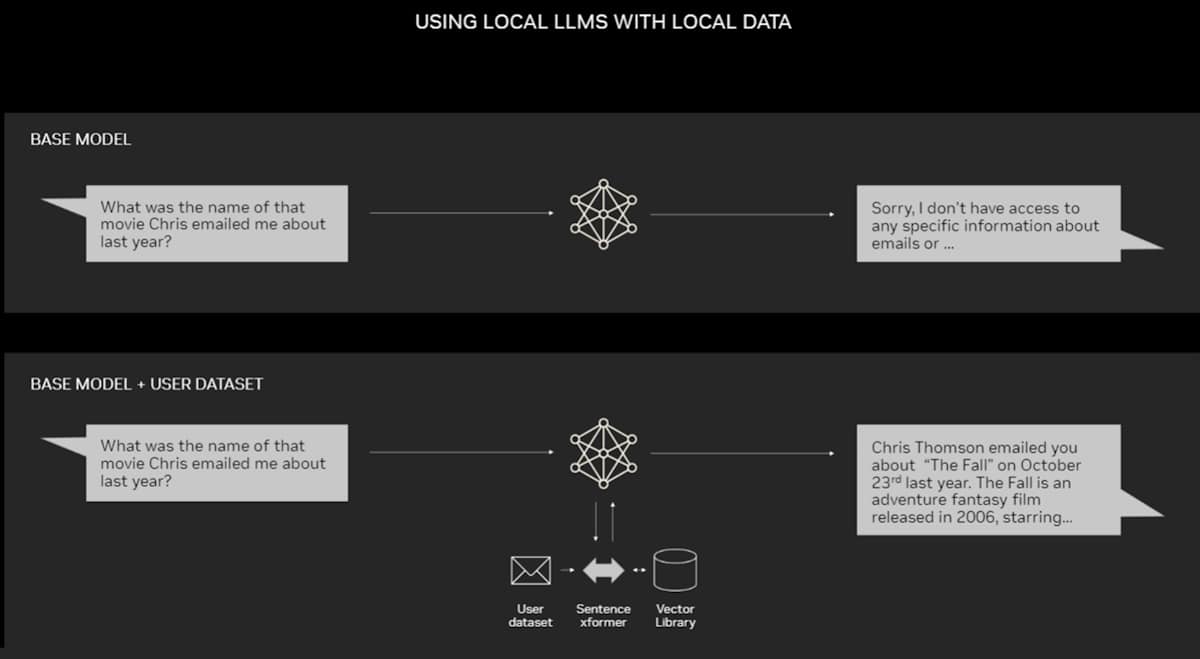 Eine Beispielanwendung für RAG auf einem PC.
Eine Beispielanwendung für RAG auf einem PC.
PCs, die mit NVIDIA RTX-GPUs ausgestattet sind, können manche KI-Modelle jetzt lokal ausführen. Durch die Verwendung von RAG auf einem PC können Benutzer eine Verknüpfung zu einer privaten Wissensquelle herstellen – seien es E-Mails, Notizen oder Artikel –, um Antworten zu verbessern. Benutzer können sich dabei darauf verlassen, dass ihre Datenquellen, Aufforderungen und Antworten vertraulich und geschützt bleiben.
Ein kürzlich veröffentlichter Blogbeitrag enthält ein Beispiel für RAG, das von TensorRT-LLM für Windows beschleunigt wird, um schnell bessere Ergebnisse zu erzielen.
Die Geschichte von RAG
Die Wurzeln der Technik reichen mindestens bis in die frühen 1970er Jahre zurück. Damals entwickelten Forscher aus dem Bereich Information Retrieval Prototypen von sogenannten Frage-Antwort-Systemen. Das sind Anwendungen, die Natural Language Processing (NLP) nutzen, um auf Texte zuzugreifen, zunächst zu eng begrenzten Themen wie Baseball.
Das Konzept hinter dieser Art von Text-Mining ist im Laufe der Jahre ziemlich konstant geblieben. Die Engines für maschinelles Lernen, die diese Techniken steuern, sind jedoch erheblich gewachsen und haben an Nutzen und Beliebtheit gewonnen.
Mitte der 1990er Jahre machte der Ask-Jeeves-Service, inzwischen Ask.com genannt, die Beantwortung von Fragen mit seinem gut gekleideten Butler als Maskottchen populär. Watson von IBM wurde 2011 zu einer TV-Berühmtheit, als er bei der Gameshow Jeopardy! zwei menschliche Champions schlug.
Heute heben LLMs Frage-Antwort-Systeme auf ein völlig neues Niveau.
Insights From a London Lab
Das wegweisende Forschungspapier, das 2020 erschien, als Lewis am University College London in NLP promovierte und für Meta in einem neuen KI-Labor in London arbeitete. Das Team suchte nach Wegen, mehr Wissen in die Parameter eines LLMs zu packen und den Fortschritt mithilfe eines selbst entwickelten Benchmarks zu messen.
Aufbauend auf früheren Methoden und inspiriert von einem Forschungspapier von Google-Forschern hatte die Gruppe „die vielversprechende Vision eines trainierten Systems, das einen Retrieval Index im Zentrum hat, sodass es jede beliebige Art von Textausgabe erlernen und generieren kann“, erinnert sich Lewis.
 Das Frage-Antwort-System IBM Watson wurde zu einer Berühmtheit, als es in der Gameshow Jeopardy! (US-Fernsehshow, die „Wer wird Millionär?“ ähnelt) die menschlichen Konkurrenten hinter sich ließ und gewann!
Das Frage-Antwort-System IBM Watson wurde zu einer Berühmtheit, als es in der Gameshow Jeopardy! (US-Fernsehshow, die „Wer wird Millionär?“ ähnelt) die menschlichen Konkurrenten hinter sich ließ und gewann!
Als Lewis ein vielversprechendes Retrieval-System eines anderen Meta-Teams in die laufende Arbeit einbezog, waren die ersten Ergebnisse unerwartet gut.
„Das habe ich meinem Vorgesetzten gezeigt, der meinte: ‚Wow, da hast du einen Volltreffer gelandet; solche Dinge passieren nicht oft‘, da die richtige Einrichtung solcher Workflows beim ersten Mal sehr schwierig sein kann“, berichtet er.
Lewis schreibt wichtige Beiträge außerdem den Teammitgliedern Ethan Perez und Douwe Kiela (damals New York University bzw. Facebook AI Research) zu.
Nach Abschluss der Arbeit, die auf einem Cluster mit NVIDIA-GPUs ausgeführt wurde, zeigte sich, wie generative KI-Modelle zuverlässiger und vertrauenswürdiger gemacht werden können. Seitdem wurde die Arbeit in Hunderten von Artikeln zitiert, die die Konzepte in einem nach wie vor aktiven Forschungsbereich erweitern und ausbauen.
Die Funktionsweise von Retrieval-Augmented Generation
Hier finden Sie eine detaillierte technische Übersicht von NVIDIA zum RAG-Prozess.
Wenn Benutzer einem LLM eine Frage stellen, sendet das KI-Modell die Abfrage an ein anderes Modell, das die Abfrage in ein numerisches, von Maschinen lesbares Format konvertiert. Die numerische Version der Abfrage wird manchmal als Einbettung oder Vektor bezeichnet.
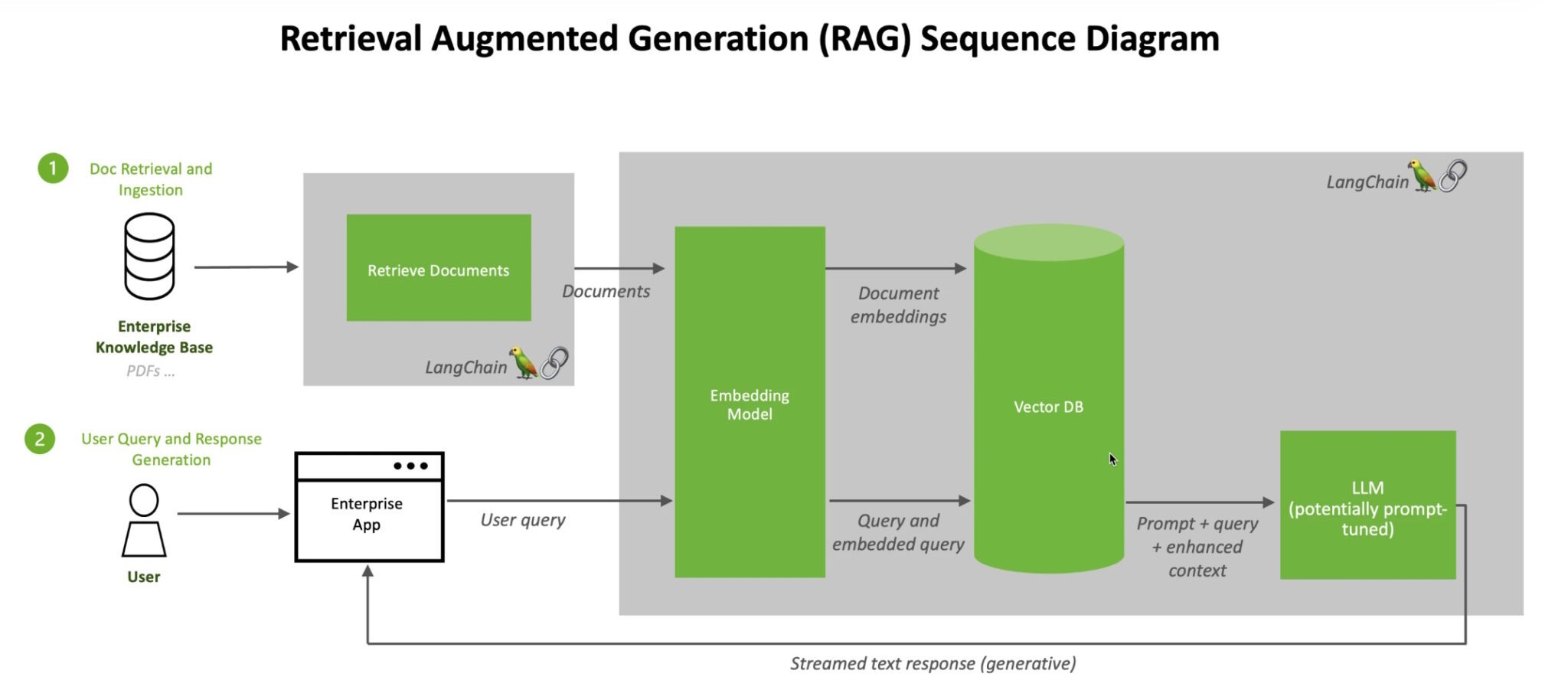 Retrieval-Augmented Generation kombiniert LLMs mit Einbettungsmodellen und Vektordatenbanken.
Retrieval-Augmented Generation kombiniert LLMs mit Einbettungsmodellen und Vektordatenbanken.
Das Einbettungsmodell vergleicht die numerischen Werte dann mit Vektoren in einem maschinenlesbaren Index einer verfügbaren Wissensdatenbank. Wenn es eine oder mehrere Übereinstimmungen gibt, ruft es die zugehörigen Daten ab, konvertiert sie in für Menschen lesbare Wörter und gibt sie an das LLM zurück.
Schließlich kombiniert das LLM die abgerufenen Wörter und die eigene Antwort auf die Abfrage zu einer abschließenden Antwort, die dem Benutzer präsentiert wird, wobei ggf. Quellen zitiert werden, die das Einbettungsmodell gefunden hat.
Quellen auf dem neuesten Stand halten
Im Hintergrund erstellt und aktualisiert das Einbettungsmodell kontinuierlich maschinenlesbare Indizes (manchmal auch als Vektordatenbanken bezeichnet) für neue und aktualisierte Wissensdatenbanken, sobald sie verfügbar werden.
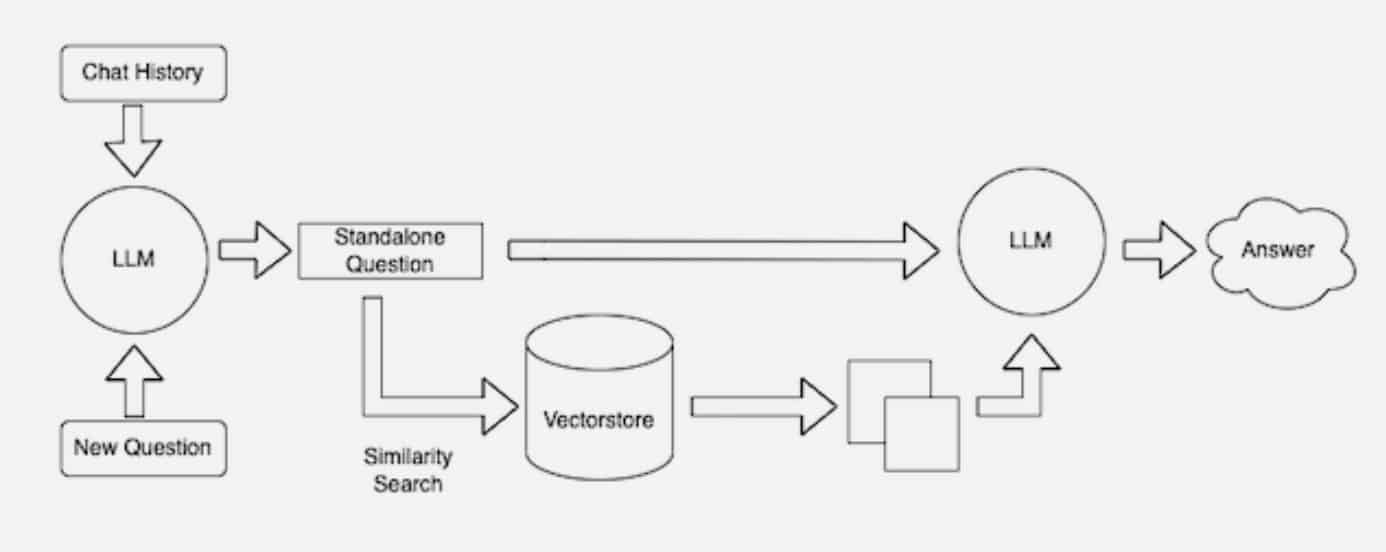 Retrieval-Augmented Generation kombiniert LLMs mit Einbettungsmodellen und Vektordatenbanken.
Retrieval-Augmented Generation kombiniert LLMs mit Einbettungsmodellen und Vektordatenbanken.
Viele Entwickler finden, dass LangChain, eine Open-Source-Bibliothek, besonders nützlich bei der Verkettung von LLMs, Einbettungsmodellen und Wissensdatenbanken ist. NVIDIA nutzt LangChain in seiner Referenzarchitektur für Retrieval-Augmented Generation.
Die LangChain-Community bietet eine eigene Beschreibung eines RAG-Prozesses.
Die Zukunft generativer KI liegt darin, alle Arten von LLMs und Wissensdatenbanken kreativ miteinander zu verknüpfen, damit sich neue Arten von Assistenten entwickeln lassen, die zuverlässige Ergebnisse liefern, welche von Benutzern verifiziert werden können.