
Ein Blick unter die Haube praktisch aller heutigen Frontier-Modelle offenbart eine MoE-Modellarchitektur (Mixture of Experts), die die Effizienz des menschlichen Gehirns nachahmt.
Genauso wie das Gehirn je nach Aufgabe bestimmte Regionen aktiviert, teilen MoE-Modelle die Arbeit unter spezialisierten „Experten” auf und aktivieren nur die für jedes KI-Token relevanten. Dies führt zu einer schnelleren, effizienteren Generierung ohne proportionale Erhöhung der Rechenleistung.
Die Branche hat diesen Vorteil bereits erkannt. In der unabhängigen Rangliste von Artificial Analysis verwenden die zehn intelligentesten Open-Source-Modelle eine MoE-Architektur, darunter DeepSeek AI’s DeepSeek-R1, Moonshot AI’s Kimi K2 Thinking, OpenAI’s gpt-oss-120B und Mistral AI’s Mistral Large 3.
Allerdings ist es bekanntermaßen schwierig, MoE-Modelle in der Produktion zu skalieren und gleichzeitig eine hohe Leistung zu erzielen. Das extreme Co-Design des NVIDIA GB200 NVL72 kombiniert Hardware- und Software-Optimierungen für maximale Leistung und Effizienz, wodurch die Skalierung von MoE-Modellen praktisch und unkompliziert wird.
Das Kimi K2 Thinking MoE-Modell – das auf der AA-Rangliste als intelligentestes Open-Source-Modell eingestuft ist – erzielt auf dem Rack-Scale-System NVIDIA GB200 NVL72 eine 10-fache Leistungssteigerung im Vergleich zu NVIDIA HGX H200. Aufbauend auf der Leistung der Modelle DeepSeek-R1 und Mistral Large 3 MoE unterstreicht dieser Durchbruch, wie MoE zur Architektur der Wahl für Frontier-Modelle wird – und warum die Full-Stack-Inferenzplattform von NVIDIA der entscheidende Faktor ist, um ihr volles Potenzial auszuschöpfen.
Was ist MoE und warum ist es zum Standard für Frontier-Modelle geworden?
Bis vor kurzem bestand der Industriestandard für die Entwicklung intelligenterer KI einfach darin, größere, dichtere Modelle zu erstellen, die alle ihre Modellparameter – bei den leistungsfähigsten Modellen von heute oft Hunderte von Milliarden – zur Generierung jedes Tokens nutzen. Dieser Ansatz ist zwar leistungsstark, erfordert jedoch immense Rechenleistung und Energie, was die Skalierung erschwert.
Ähnlich wie das menschliche Gehirn bestimmte Regionen für unterschiedliche kognitive Aufgaben nutzt – sei es die Verarbeitung von Sprache, das Erkennen eines Gesichts oder das Lösen einer mathematischen Aufgabe –, bestehen MoE-Modelle aus mehreren spezialisierten „Experten”. Für jedes beliebige Token werden nur die relevantesten von einem Router aktiviert. Dieses Design bedeutet, dass selbst wenn das Gesamtmodell Hunderte von Milliarden von Parametern enthält, für die Generierung eines Tokens nur eine kleine Teilmenge verwendet wird – oft nur einige wenige Milliarden.
So wie das menschliche Gehirn bestimmte Bereiche für unterschiedliche Aufgaben nutzt, verwenden Mixture-of-Experts-Modelle einen Router, um nur die relevantesten Experten für die Generierung jedes Tokens auszuwählen.
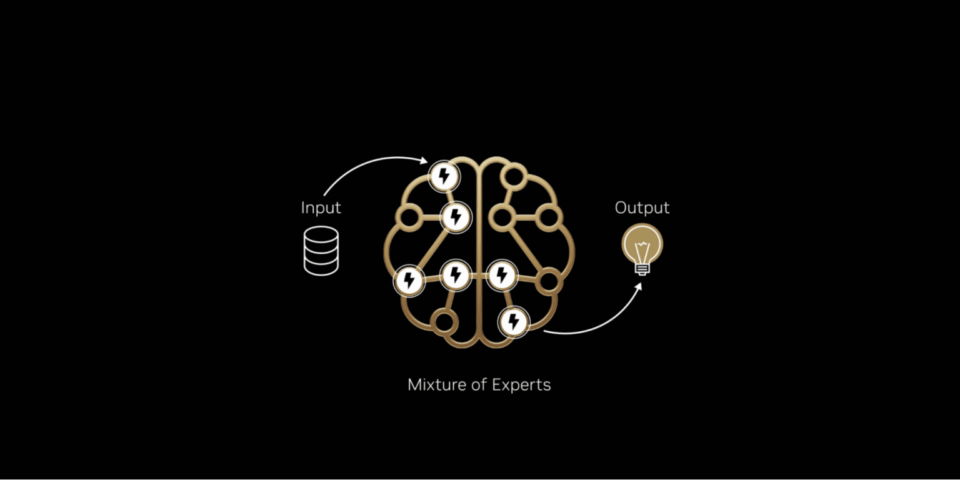
Ein Diagramm mit dem Titel „Mixture of Experts”, das die KI-Architektur veranschaulicht. Ein stilisiertes Gehirnnetzwerk befindet sich zwischen einem „Input”-Daten-Symbol und einem „Output”-Glühbirnen-Symbol. Innerhalb des Gehirns sind bestimmte Knoten mit Blitzsymbolen hervorgehoben, um visuell zu demonstrieren, dass nur relevante „Experten” aktiviert werden, um jedes Token zu generieren, anstatt das gesamte Netzwerk.
Durch die selektive Einbeziehung nur der wichtigsten Experten erreichen MoE-Modelle eine höhere Intelligenz und Anpassungsfähigkeit, ohne dass die Rechenkosten entsprechend steigen. Dies macht sie zur Grundlage für effiziente KI-Systeme, die auf Leistung pro Dollar und pro Watt optimiert sind – und somit deutlich mehr Intelligenz pro investierter Energie- und Kapitaleinheit generieren.
Angesichts dieser Vorteile ist es nicht verwunderlich, dass MoE schnell zur bevorzugten Architektur für Frontier-Modelle geworden ist und in diesem Jahr von über 60 % der veröffentlichten Open-Source-KI-Modelle übernommen wurde. Seit Anfang 2023 hat es eine fast 70-fache Steigerung der Modellintelligenz ermöglicht und damit die Grenzen der KI-Fähigkeiten erweitert.
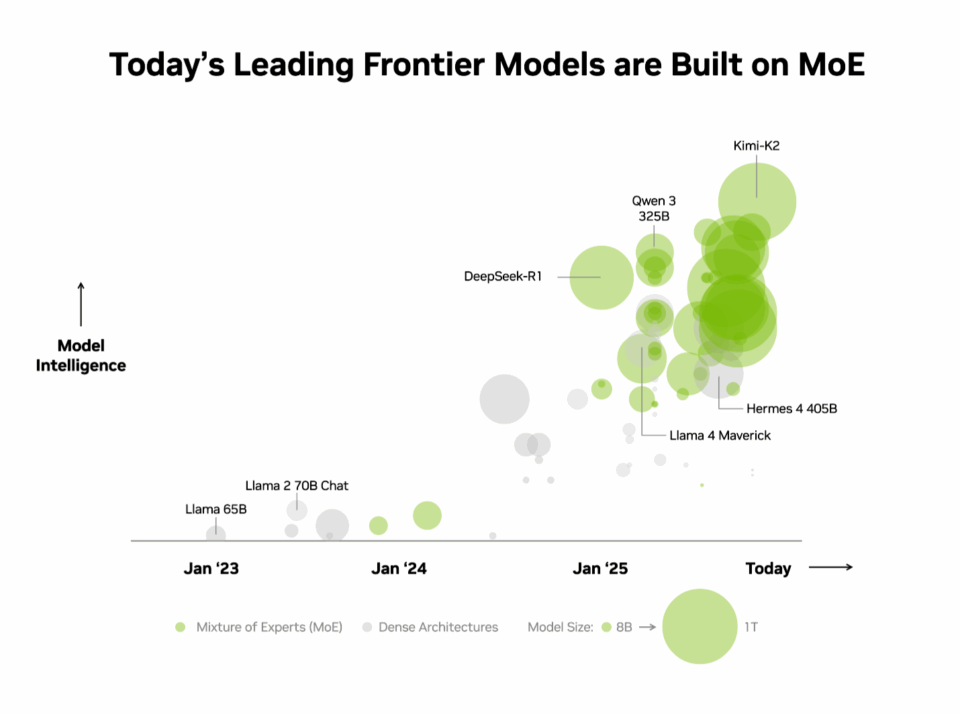
Seit Anfang 2025 verwenden fast alle führenden Frontier-Modelle MoE-Designs.
„Unsere Pionierarbeit mit der OSS Mixture-of-Experts-Architektur, die vor zwei Jahren mit Mixtral 8x7B begann, stellt sicher, dass fortschrittliche Intelligenz für eine Vielzahl von Anwendungen sowohl zugänglich als auch nachhaltig ist“, sagte Guillaume Lample, Mitbegründer und Chief Scientist bei Mistral AI. „Die MoE-Architektur von Mistral Large 3 ermöglicht es uns, KI-Systeme leistungsfähiger und effizienter zu skalieren und gleichzeitig den Energie- und Rechenbedarf drastisch zu senken.“
Überwindung von MoE-Skalierungsengpässen mit Extreme Codesign
Modernste MoE-Modelle sind einfach zu groß und zu komplex, um auf einer einzigen GPU eingesetzt zu werden. Um sie auszuführen, müssen die Experten auf mehrere GPUs verteilt werden, eine Technik, die als Expertenparallelismus bezeichnet wird. Selbst auf leistungsstarken Plattformen wie der NVIDIA H200 bringt der Einsatz von MoE-Modellen Engpässe mit sich, wie zum Beispiel
- Speicherbeschränkungen: Für jedes Token müssen GPUs die Parameter der ausgewählten Experten dynamisch aus dem Speicher mit hoher Bandbreite laden, was häufig zu einer starken Belastung der Speicherbandbreite führt.
- Latenz: Experten müssen ein nahezu sofortiges All-to-All-Kommunikationsmuster ausführen, um Informationen auszutauschen und eine endgültige, vollständige Antwort zu bilden. Bei H200 müssen Experten jedoch auf mehr als acht GPUs verteilt werden, was eine Kommunikation über Scale-Out-Netzwerke mit höherer Latenz erfordert, wodurch die Vorteile der Expertenparallelität eingeschränkt werden.
Die Lösung: extremes Co-Design.
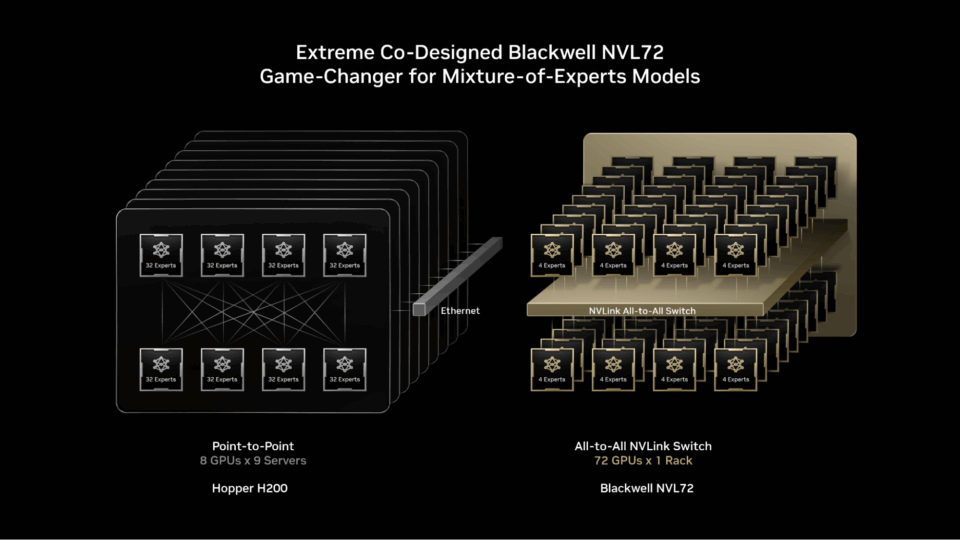
NVIDIA GB200 NVL72 ist ein Rack-Scale-System mit 72 NVIDIA Blackwell-GPUs, die zusammenarbeiten, als wären sie eine einzige GPU, und eine KI-Leistung von 1,4 ExaFlops sowie 30 TB schnellen gemeinsamen Speicher bieten. Die 72 GPUs sind über NVLink Switch zu einer einzigen, massiven NVLink-Verbindungsstruktur verbunden, die es jeder GPU ermöglicht, mit einer NVLink-Konnektivität von 130 TB/s miteinander zu kommunizieren.
MoE-Modelle können dieses Design nutzen, um die Parallelität von Experten weit über die bisherigen Grenzen hinaus zu skalieren – indem sie die Experten auf eine viel größere Gruppe von bis zu 72 GPUs verteilen.
Dieser architektonische Ansatz löst MoE-Skalierungsengpässe direkt, indem er
- Reduzierung der Anzahl der Experten pro GPU: Durch die Verteilung der Experten auf bis zu 72 GPUs wird die Anzahl der Experten pro GPU reduziert, wodurch die Belastung des Hochbandbreitenspeichers jeder GPU durch das Laden von Parametern minimiert wird. Weniger Experten pro GPU setzen außerdem Speicherplatz frei, sodass jede GPU mehr gleichzeitige Benutzer bedienen und längere Eingaben unterstützen kann.
- Beschleunigung der Kommunikation zwischen den Experten: Die auf die GPUs verteilten Experten können über NVLink sofort miteinander kommunizieren. Der Switch selbst verfügt auch über die Rechenleistung, die für einige der Berechnungen erforderlich ist, um die Informationen der verschiedenen Experten zu kombinieren, wodurch die endgültige Antwort beschleunigt wird.
Andere Full-Stack-Optimierungen spielen ebenfalls eine wichtige Rolle bei der Erzielung einer hohen Inferenzleistung für MoE-Modelle. Das NVIDIA Dynamo-Framework koordiniert die disaggregierte Bereitstellung, indem es Vorfüll- und Dekodierungsaufgaben verschiedenen GPUs zuweist, sodass die Dekodierung mit hoher Parallelität ausgeführt werden kann, während die Vorfüllung Parallelitätstechniken nutzt, die besser für ihre Arbeitslast geeignet sind. Das NVFP4-Format trägt dazu bei, die Genauigkeit zu erhalten und gleichzeitig die Leistung und Effizienz weiter zu steigern.
Open-Source-Inferenz Frameworks wie NVIDIA TensorRT-LLM, SGLang und vLLM unterstützen diese Optimierungen für MoE-Modelle. Insbesondere SGLang hat eine wichtige Rolle bei der Weiterentwicklung von groß angelegten MoE auf GB200 NVL72 gespielt und dazu beigetragen, viele der heute verwendeten Techniken zu validieren und ausgereift zu machen.
Um diese Leistung Unternehmen weltweit zugänglich zu machen, wird GB200 NVL72 von allen großen Cloud-Dienstleistern und NVIDIA Cloud-Partnern wie Amazon Web Services, Core42, CoreWeave, Crusoe, Google Cloud, Lambda, Microsoft Azure, Nebius, Nscale, Oracle Cloud Infrastructure, Together AI und weiteren eingesetzt.
„CoreWeave Kunden nutzen unsere Plattform, um Mixture-of-Experts-Modelle in die Produktion zu bringen, während sie agentenbasierte Workflows erstellen“, erklärte Peter Salanki, Mitbegründer und Chief Technology Officer bei CoreWeave. „Durch die enge Zusammenarbeit mit NVIDIA sind wir in der Lage, eine eng integrierte Plattform bereitzustellen, die MoE-Leistung, Skalierbarkeit und Zuverlässigkeit an einem Ort vereint. Dies ist nur auf einer speziell für KI entwickelten Cloud möglich.“
Kunden wie DeepL nutzen das Rack-Scale-Design Blackwell NVL72, um ihre KI-Modelle der nächsten Generation zu entwickeln und einzusetzen.
„DeepL nutzt NVIDIA GB200-Hardware, um Mixture-of-Experts-Modelle zu trainieren, seine Modellarchitektur zu verbessern, um die Effizienz während des Trainings und der Inferenz zu steigern, und neue Maßstäbe für die Leistung im Bereich der KI zu setzen“, sagte Paul Busch, Leiter des Forschungsteams bei DeepL.
Der Beweis liegt in der Leistung pro Watt
NVIDIA GB200 NVL72 skaliert komplexe MoE-Modelle effizient und liefert eine 10-fache Leistungssteigerung pro Watt. Dieser Leistungssprung ist nicht nur ein Benchmark, sondern ermöglicht auch eine 10-fache Steigerung der Token-Erträge und verändert damit die Wirtschaftlichkeit von KI in großem Maßstab in Rechenzentren mit begrenzter Leistung und begrenzten Kosten.
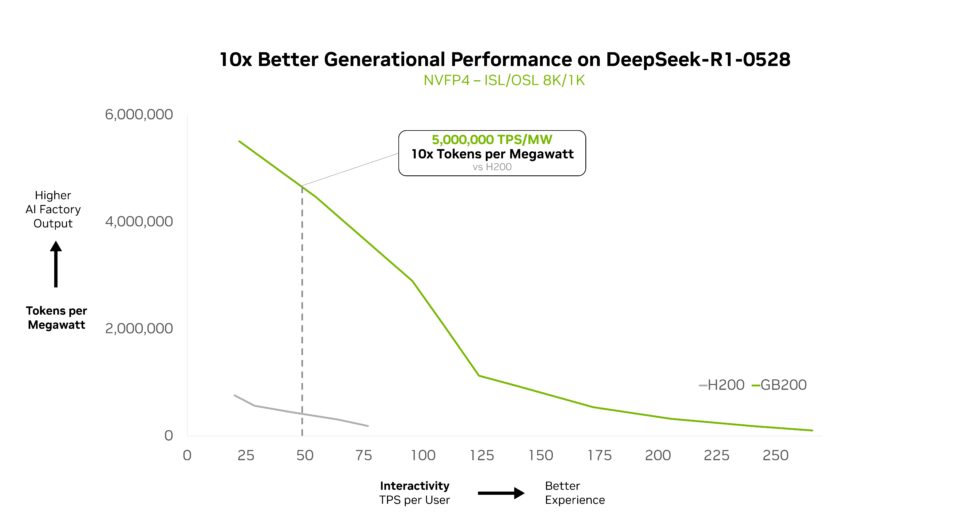
Auf der NVIDIA GTC in Washington, D.C., hob Jensen Huang, Gründer und CEO von NVIDIA, hervor, dass GB200 NVL72 die zehnfache Leistung von NVIDIA Hopper für DeepSeek-R1 bietet und dass sich diese Leistung auch auf andere DeepSeek-Varianten erstreckt.
„Mit GB200 NVL72 und den maßgeschneiderten Optimierungen von Together AI übertreffen wir die Erwartungen unserer Kunden hinsichtlich groß angelegter Inferenz-Workloads für MoE-Modelle wie DeepSeek-V3“, so Vipul Ved Prakash, Mitbegründer und CEO von Together AI. „Die Leistungssteigerungen sind auf die Full-Stack-Optimierungen von NVIDIA in Verbindung mit den bahnbrechenden Innovationen von Together AI Inference in den Bereichen Kernel, Laufzeit-Engine und spekulative Decodierung zurückzuführen.“
Dieser Leistungsvorteil erstreckt sich auch auf andere Frontier-Modelle.
Kimi K2 Thinking, das intelligenteste Open-Source-Modell, ist ein weiterer Beweis dafür und erzielt eine 10-mal bessere Generationsleistung, wenn es auf GB200 NVL72 eingesetzt wird.
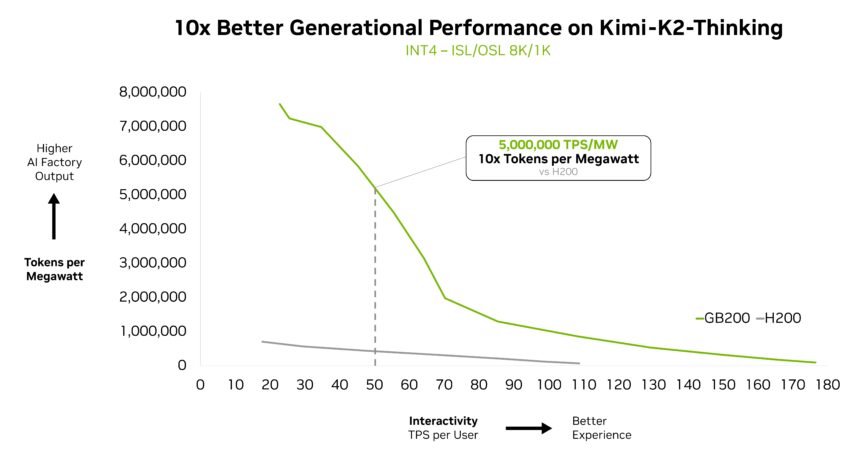
Fireworks AI hat dieses Modell auf der NVIDIA B200-Plattform eingesetzt, um die höchste Leistung in der Rangliste für künstliche Analyse zu erzielen.
„Das Rack-Scale-Design von NVIDIA GB200 NVL72 macht den Einsatz von MoE-Modellen deutlich effizienter“, so Lin Qiao, CEO von Fireworks AI. „In der Zukunft hat NVL72 das Potenzial, die Art und Weise, wie wir umfangreiche MoE-Modelle bedienen, zu revolutionieren, indem es gegenüber der Hopper-Plattform erhebliche Leistungsverbesserungen bietet und neue Maßstäbe für die Geschwindigkeit und Effizienz von Spitzenmodellen setzt.“
Das neue Mistral Large 3 Modell erzielte außerdem eine 10-fache Leistungssteigerung auf dem GB200 NVL72 im Vergleich zur Vorgängergeneration H200. Diese generationsbedingte Leistungssteigerung führt zu einer besseren Benutzererfahrung, geringeren Kosten pro Token und einer höheren Energieeffizienz für dieses neue MoE-Modell.
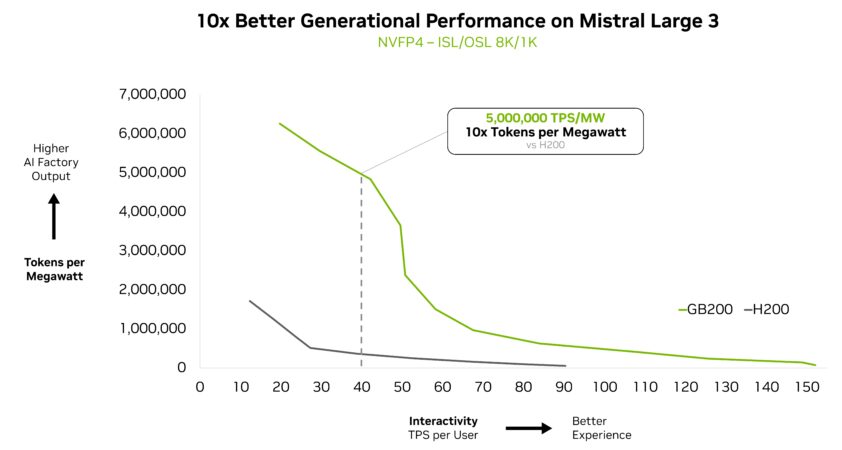
Intelligenz in großem Maßstab
Das Rack-Scale-System NVIDIA GB200 NVL72 wurde entwickelt, um eine starke Leistung über MoE-Modelle hinaus zu liefern.
Der Grund dafür wird deutlich, wenn man sich ansieht, wohin sich die KI entwickelt: Die neueste Generation multimodaler KI-Modelle verfügt über spezialisierte Komponenten für Sprache, Bildverarbeitung, Audio und andere Modalitäten, wobei nur die für die jeweilige Aufgabe relevanten Komponenten aktiviert werden.
In agentenbasierten Systemen sind verschiedene „Agenten“ auf Planung, Wahrnehmung, Schlussfolgerungen, Werkzeuggebrauch oder Suche spezialisiert, und ein Orchestrator koordiniert sie, um ein einziges Ergebnis zu erzielen. In beiden Fällen spiegelt das Kernmuster MoE wider: Jeder Teil des Problems wird an die relevantesten Experten weitergeleitet, deren Ergebnisse dann koordiniert werden, um das Endergebnis zu erzielen.
Die Ausweitung dieses Prinzips auf Produktionsumgebungen, in denen mehrere Anwendungen und Agenten mehrere Benutzer bedienen, eröffnet neue Effizienzstufen. Anstatt massive KI-Modelle für jeden Agenten oder jede Anwendung zu duplizieren, ermöglicht dieser Ansatz einen gemeinsamen Pool von Experten, auf den alle zugreifen können, wobei jede Anfrage an den richtigen Experten weitergeleitet wird.
Mixture of Experts ist eine leistungsstarke Architektur, die die Branche in eine Zukunft führt, in der enorme Leistungsfähigkeit, Effizienz und Skalierbarkeit nebeneinander existieren. Der GB200 NVL72 erschließt dieses Potenzial bereits heute, und die Roadmap von NVIDIA mit der NVIDIA Vera Rubin-Architektur wird die Horizonte der Frontier-Modelle weiter erweitern.
Weitere Informationen darüber, wie GB200 NVL72 komplexe MoE-Modelle skaliert, finden Sie in diesem technischen Deep Dive.
Dieser Beitrag ist Teil von Think SMART, einer Reihe, die sich darauf konzentriert, wie führende KI-Dienstleister, Entwickler und Unternehmen ihre Inferenzleistung und Kapitalrendite mit den neuesten Fortschritten der Full-Stack-Inferenzplattform von NVIDIA steigern können.