
KI schafft einen Mehrwert für alle – von Forschern in der Medikamentenentwicklung bis hin zu quantitativen Analysen, die sich mit den Veränderungen auf den Finanzmärkten beschäftigen.
Je schneller ein KI-System Token erzeugen kann, eine Dateneinheit, die zum Zusammenführen von Ausgaben verwendet wird, desto größer ist seine Wirkung. Deshalb sind KI-Fabriken entscheidend, denn sie bieten den effizientesten Weg von der „Zeit bis zum ersten Token“ zur „Zeit bis zur ersten Wertschöpfung“.
KI-Fabriken definieren die Wirtschaftlichkeit moderner Infrastruktur neu. Sie erzeugen Intelligenzleistungen, indem sie Daten in großem Umfang in wertvolle Ausgaben umwandeln – ob Token, Vorhersagen, Bilder, Proteine oder andere Formen.
Sie tragen dazu bei, drei wichtige Aspekte der KI-Reise zu verbessern: Datenaufnahme, Modelltraining und Inferenz mit hohem Volumen. KI-Fabriken werden gebaut, um Token schneller und genauer zu generieren, wobei drei kritische Technologie-Stacks verwendet werden: KI-Modelle, beschleunigte Recheninfrastruktur und Software für Unternehmen.
Lesen Sie weiter und erfahren Sie, wie KI-Fabriken Unternehmen und Organisationen auf der ganzen Welt dabei helfen, den wertvollsten digitalen Rohstoff – Daten – in potenzielle Umsätze zu verwandeln.
Von der Inferenzökonomie zur Wertschöpfung
Bevor Sie eine KI-Fabrik aufbauen, müssen Sie die Wirtschaftlichkeit von Inferenz begreifen – wie Sie also Kosten, Energieeffizienz und die steigende Nachfrage nach KI in Einklang bringen.
Der Durchsatz bezieht sich auf das Volumen der Token, die ein Modell produzieren kann. Die Latenz ist die Anzahl der Token, die das Modell in einer bestimmten Zeit ausgeben kann, die oft als Zeit bis zum ersten Token gemessen wird – wie lange es dauert, bis die erste Ausgabe erstellt wurde – und als Zeit pro Ausgangstoken bzw. wie schnell jeder weitere Token ausgegeben wird. Goodput ist eine neuere Metrik, die bemisst, welche Menge an nützlichen Ausgaben ein System liefern kann, während es wichtige Latenzziele erreicht.
Die Benutzererfahrung ist für jede Softwareanwendung von entscheidender Bedeutung und das Gleiche gilt für KI-Fabriken. Ein hoher Durchsatz bedeutet intelligentere KI und eine geringere Latenz sorgt für zeitnahe Antworten. Wenn beide Größen ausgewogen sind, können KI-Fabriken durch die schnelle Bereitstellung hilfreicher Ausgaben eine ansprechende Benutzererfahrung bieten.
So ist beispielsweise ein KI-gestützter Kundendienstagent, der in einer halben Sekunde antwortet, weitaus ansprechender und wertvoller als einer, der in fünf Sekunden antwortet, selbst wenn beide mit der Antwort letztendlich die gleiche Anzahl an Token generieren
Unternehmen können wettbewerbsfähige Preise für ihre Inferenz-Ausgaben festlegen, was zu mehr potenziellem Umsatz pro Token führt.
Diese Balance zu messen und zu visualisieren kann schwierig sein – hier kommt das Konzept der Pareto-Grenze ins Spiel.
Ausgaben einer KI-Fabrik: Der Wert effizienter Token
Die nachfolgend abgebildete Pareto-Grenze hilft bei der Visualisierung der optimalen Möglichkeiten, konkurrierende Ziele bei der Bereitstellung von KI in großem Umfang ins Gleichgewicht zu bringen – etwa schnellere Antworten vs. gleichzeitige Bedienung mehrerer Benutzer.
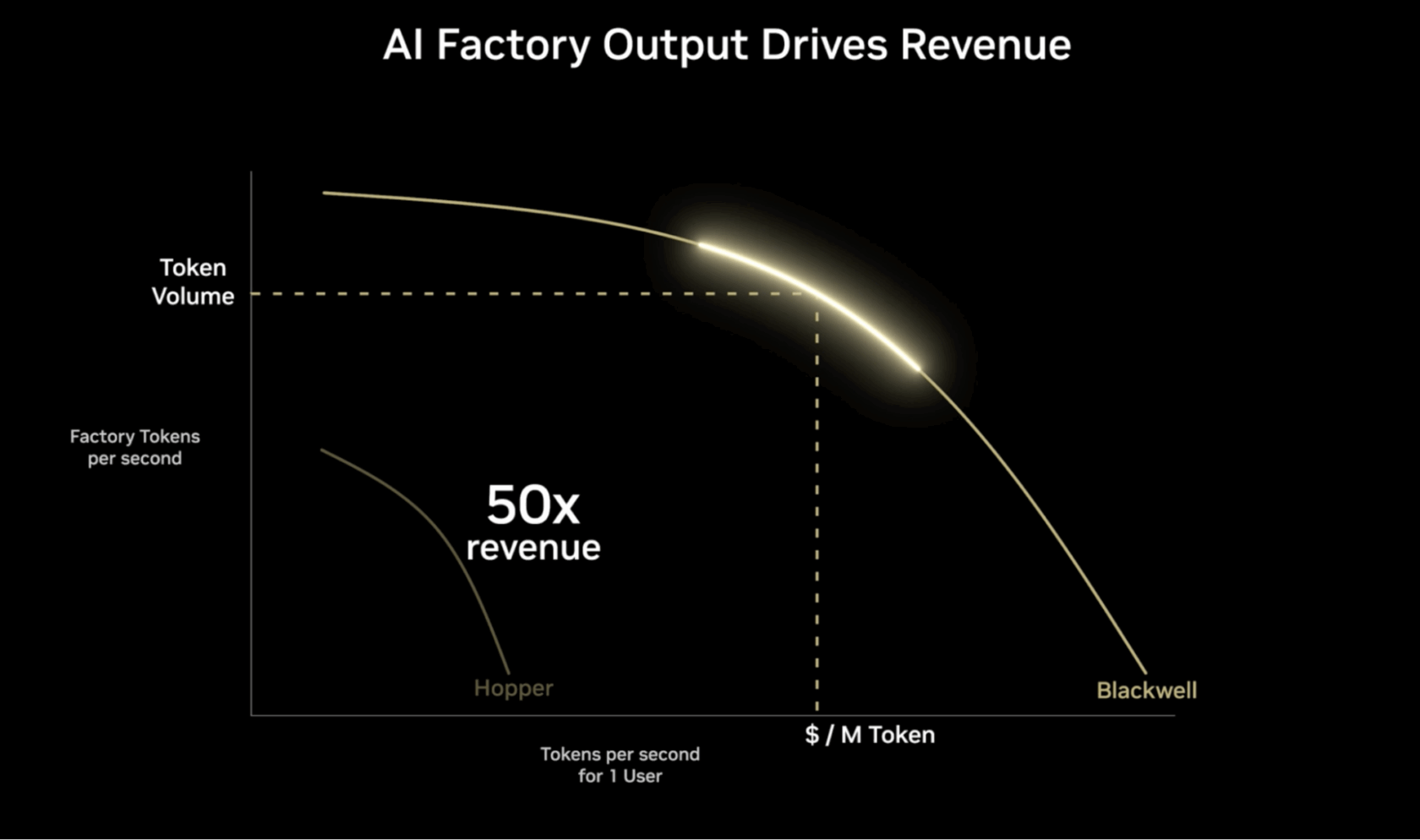
Die vertikale Achse stellt die Durchsatzleistung, gemessen in Token pro Sekunde (TPS), für eine bestimmte Menge an verbrauchter Energie dar. Je höher diese Zahl, desto mehr Anfragen kann eine KI-Fabrik gleichzeitig bearbeiten.
Die horizontale Achse stellt die TPS für einen einzelnen Benutzer dar und gibt an, wie lange es dauert, bis ein Modell einem Benutzer die erste Antwort auf einen Prompt gibt. Je höher der Wert, desto besser ist die erwartete Benutzererfahrung. Geringere Latenzzeiten und schnellere Reaktionszeiten sind generell für interaktive Anwendungen wie Chatbots und Echtzeit-Analysetools wünschenswert.
Der maximale Wert der Pareto-Grenze – als oberster Wert der Kurve dargestellt – stellt die beste Ausgabe für eine gegebene Betriebskonfiguration dar. Ziel ist es, die optimale Balance zwischen Durchsatz und Benutzererfahrung für verschiedene KI-Workloads und -Anwendungen zu finden.
Die besten KI-Fabriken nutzen beschleunigtes Computing, um Token pro Watt zu erhöhen – was die KI-Leistung optimiert und gleichzeitig die Energieeffizienz der KI-Fabriken und -Anwendungen drastisch erhöht.

Die obige Animation vergleicht die Benutzererfahrung bei der Ausführung auf NVIDIA H100-GPUs, konfiguriert für die Ausführung mit 32 Token pro Sekunde pro Benutzer, mit NVIDIA B300-GPUs, die 344 Token pro Sekunde pro Benutzer verwenden. Für die konfigurierte Benutzererfahrung bietet Blackwell Ultra eine mehr als 10-fach bessere Benutzererfahrung und einen fast 5-mal höheren Durchsatz, was ein bis zu 50-mal höheres Umsatzpotenzial eröffnet.
So funktioniert eine KI-Fabrik in der Praxis
Eine KI-Fabrik ist ein System von Komponenten, die zusammenkommen, um Daten in Intelligenzleistungen umzuwandeln. Die Fabrik muss nicht unbedingt ein lokales High-End-Rechenzentrum sein, sie könnte auch eine auf KI spezialisierte Cloud oder ein hybrides Modell sein, das auf einer beschleunigten Recheninfrastruktur läuft. Oder sie könnte eine Telekommunikationsinfrastruktur sein, die sowohl das Netzwerk optimieren als auch Inferenzen im Edge durchführen kann.
Jede dedizierte beschleunigte Recheninfrastruktur, die mit Software kombiniert wird, die Daten durch KI in Intelligenzleistungen verwandelt, ist letztendlich eine KI-Fabrik.
Die Komponenten umfassen beschleunigtes Computing, Netzwerke, Software, Speicher, Systeme sowie Tools und Services.
Wenn eine Person einen Prompt an ein KI-System sendet, geht der volle Stack der KI-Fabrik an die Arbeit. Die Fabrik tokenisiert den Prompt und verwandelt Daten in kleine Bedeutungseinheiten – etwa Fragmente von Bildern, Geräuschen und Wörtern.
Jedes Token wird durch ein GPU-gestütztes KI-Modell geleitet, das rechenintensives Reasoning auf dem KI-Modell durchführt, um die beste Antwort zu erzeugen. Jede GPU führt parallele Verarbeitungen durch – ermöglicht durch Hochgeschwindigkeitsnetzwerke und Konnektivität –, um Daten gleichzeitig zu verarbeiten.
Eine KI-Fabrik führt diesen Prozess für verschiedene Prompts von Benutzern auf der ganzen Welt aus. Diese Echtzeit-Inferenz erzeugt Intelligenzleistungen in industriellen Maßstab.
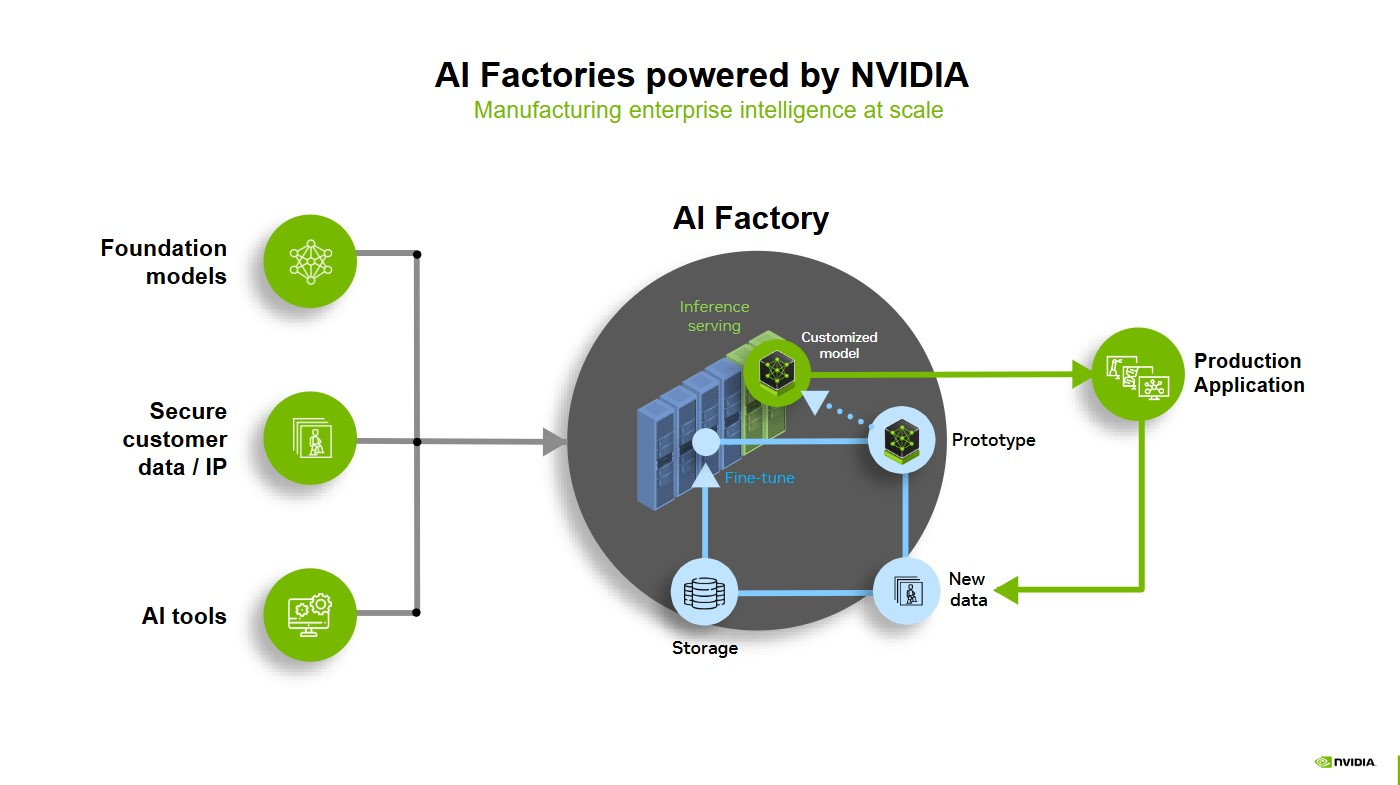
Da KI-Fabriken den gesamten KI-Lebenszyklus vereinheitlichen, verbessert sich dieses System kontinuierlich selbst: Inferenz wird protokolliert, Randerscheinungen werden für erneutes Training markiert und Optimierungsschleifen werden im Laufe der Zeit beschleunigt – alles ohne manuelles Eingreifen: Goodput in Aktion.
Das weltweit führende Unternehmen für Sicherheitstechnologie, Lockheed Martin, hat eine eigene KI-Fabrik aufgebaut, um vielfältige Anwendungen im gesamten Unternehmen zu unterstützen. Durch das Lockheed Martin AI Center konnte das Unternehmen seine generativen KI-Workloads auf NVIDIA DGX SuperPOD bündeln, um KI-Modelle zu trainieren und anzupassen, die volle Leistung spezialisierter Infrastruktur zu nutzen und die Gemeinkosten von Cloud-Umgebungen zu reduzieren.
„Unsere lokale KI-Fabrik bewältigt Tokenisierung, Training und Bereitstellung im eigenen Haus“, sagt Greg Forrest, Director of AI Foundations bei Lockheed Martin. „Unser DGX SuperPOD hilft uns, über 1 Milliarde Token pro Woche zu verarbeiten, was Feinabstimmung, Retrieval-Augmented Generation oder Inferenz auf unseren großen Sprachmodellen ermöglicht. Mit dieser Lösung vermeiden wir die eskalierenden Kosten und erheblichen Einschränkungen von tokenbasierten Gebühren.“
NVIDIA Full-Stack-Technologien für KI-Fabriken
Dank KI-Fabriken gehören isolierter Experimente der Vergangenheit an. Stattdessen wird aus KI eine skalierbare, wiederholbare und zuverlässige Triebfeder für Innovation und Geschäftswerte.
NVIDIA bietet alle Komponenten, die für den Aufbau von KI-Fabriken benötigt werden, einschließlich beschleunigtem Computing, Hochleistungs-GPUs, Netzwerken mit hoher Bandbreite und optimierter Software.
NVIDIA Blackwell-GPUs können beispielsweise über Netzwerke verbunden, energieeffizient mit Flüssigkeitskühlung gekühlt und mit KI-Software orchestriert werden.
Die NVIDIA Dynamo Open-Source-Inferenzplattform bietet ein Betriebssystem für KI-Fabriken. Sie wurde entwickelt, um KI mit maximaler Effizienz und minimalen Kosten zu beschleunigen und zu skalieren. Durch intelligentes Routing sowie intelligente Planung und Optimierung von Inferenzanforderungen stellt Dynamo sicher, dass jeder GPU-Zyklus voll ausgelastet wird und die Token-Produktion mit optimaler Leistung voranschreitet.
NVIDIA Blackwell GB200 NVL72-Systeme und NVIDIA InfiniBand-Netzwerke sind auf maximalen Token-Durchsatz pro Watt ausgelegt. Dadurch wird die KI-Fabrik sowohl in Bezug auf Gesamtdurchsatz als auch Latenz so effizient wie möglich.
Durch die Validierung optimierter Full-Stack-Lösungen können Unternehmen modernste KI-Systeme effizient erstellen und warten. Eine Full-Stack-KI-Fabrik unterstützt Unternehmen dabei, betriebliche Höchstleistungen zu erzielen und das Potenzial von KI schneller und mit größerer Sicherheit zu nutzen.
Erfahren Sie mehr darüber, wie KI-Fabriken Rechenzentren neu definieren und die nächste Ära der KI ermöglichen.Das Umsatzpotenzial von KI-Fabriken entdecken