Genauso wie es weithin anerkannte empirische Naturgesetze gibt, wie das Gesetz der Schwerkraft und Actio gleich Reactio, wurde der KI-Bereich lange Zeit von einer einzigen Idee bestimmt: dass mehr Rechenleistung, mehr Trainingsdaten und mehr Parameter ein besseres KI-Modell schaffen.
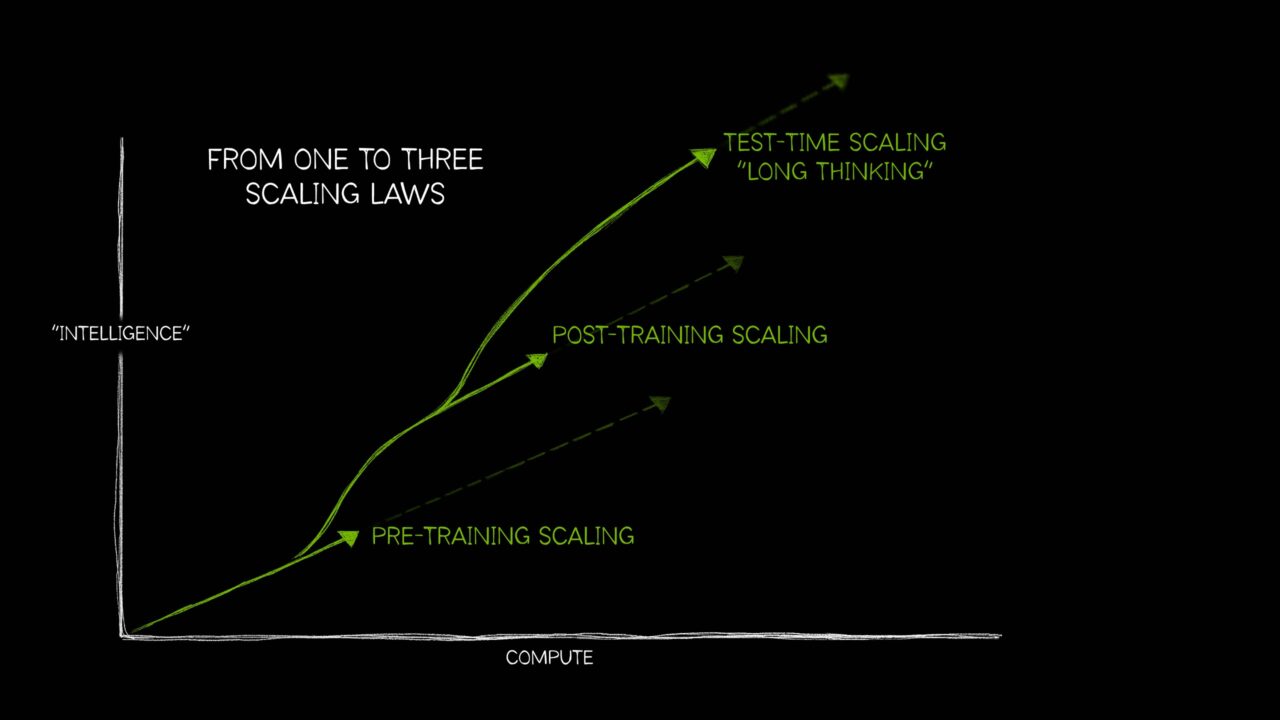
Inzwischen ist die KI jedoch so weit fortgeschritten, dass drei verschiedene Gesetze erforderlich sind, die beschreiben, wie sich der unterschiedliche Einsatz von Rechenressourcen auf die Modellleistung auswirkt. Diese Gesetze der KI-Skalierung – Pre-Training-Skalierung, Post-Training-Skalierung und Testzeit-Skalierung, auch als langes Nachdenken bezeichnet – spiegeln wider, wie sich dieses Feld mit Techniken entwickelt hat, um zusätzliche Rechenleistung in einer Vielzahl von immer komplexeren KI-Anwendungsfällen zu nutzen.
Die neuerdings verstärkt auftretende Testzeit-Skalierung – der Einsatz von mehr Rechenleistung zum Zeitpunkt der Inferenz, um die Genauigkeit zu verbessern – ermöglicht KI-Reasoning-Modelle. Dabei handelt es sich um eine neue Klasse großer Sprachmodelle (LLMs), die mehrere Inferenzdurchläufe durchführen, um komplexe Probleme zu bewältigen, und gleichzeitig die zur Lösung einer Aufgabe erforderlichen Schritte beschreiben. Die Testzeit-Skalierung erfordert intensive Mengen an Rechenressourcen zur Unterstützung des KI-Reasonings, was die Nachfrage nach beschleunigter Datenverarbeitung weiter steigern wird.
Was ist Pre-Training-Skalierung?
Pre-Training-Skalierung ist das ursprüngliche Gesetz der KI-Entwicklung. Es zeigte, dass Entwickler durch die Erhöhung der Größe des Trainingsdatensatzes, der Anzahl der Modellparameter und der Rechenressourcen vorhersehbare Steigerungen in der Intelligenz und Genauigkeit der Modelle erwarten können.
Alle drei Elemente – Daten, Modellgröße, Rechenleistung – stehen in einer Wechselbeziehung zueinander. Gemäß dem in dieser Forschungsarbeit beschriebenen Gesetz der Pre-Training-Skalierung, verbessert sich die Gesamtleistung größerer Modelle, wenn sie mit mehr Daten gespeist werden. Um dies zu ermöglichen, müssen Entwickler ihre Rechenleistung skalieren, was leistungsstarke beschleunigte Rechenressourcen für größere Trainingsworkloads erfordert.
Dieses Prinzip der Pre-Training-Skalierung führte zu großen Modellen mit bahnbrechenden Eigenschaften. Darüber hinaus führte dies zu bedeutenden Innovationen in der Modellarchitektur, einschließlich der Entwicklung von Transformatormodellen mit Milliarden oder Billionen von Parametern, Mixture-of-Experts-Modellen und neuen verteilten Trainingstechniken, die alle eine erhebliche Rechenleistung erfordern.
Die Relevanz des Gesetzes der Skalierung im Pre-Training bleibt bestehen: Da Menschen weiterhin wachsende Mengen an multimodalen Daten produzieren, wird diese Fülle an Text-, Bild-, Audio-, Video- und Sensorinformationen verwendet, um leistungsstarke zukünftige KI-Modelle zu trainieren.
Was ist Post-Training-Skalierung?
Das Pre-Training eines großen Foundation Model ist nicht für jeden geeignet. Es erfordert erhebliche Investitionen, qualifizierte Experten und Datenmengen. Sobald ein Unternehmen ein Modell vortrainiert und veröffentlicht, senkt es die Barriere für die KI-Einführung, indem es anderen ermöglicht, sein vortrainiertes Modell als Grundlage für die Anpassung an seine eigenen Anwendungen zu verwenden.
Dieser Post-Training-Prozess führt zu einer zunehmenden Nachfrage nach beschleunigtem Computing in Unternehmen und der allgemeinen Entwickler-Community. Beliebte Open-Source-Modelle können Hunderte oder Tausende von abgeleiteten Modellen enthalten, die in zahlreichen Bereichen trainiert wurden.
Die Entwicklung eines solchen Technologieumfelds mit abgeleiteten Modellen für eine Vielzahl von Anwendungsfällen würde ohne das Pre-Training des originalen Foundation Model etwa 30-mal mehr Rechenleistung erfordern.
Die Entwicklung eines solchen Technologieumfelds mit abgeleiteten Modellen für eine Vielzahl von Anwendungsfällen würde ohne das Pre-Training des originalen Foundation Model etwa 30-mal mehr Rechenleistung erfordern.
Post-Training oder Nachtrainieren kann die Spezifität und Relevanz eines Modells für den gewünschten Anwendungsfall eines Unternehmens weiter verbessern. Während das Pre-Training damit vergleichbar ist, ein KI-Modell in eine Schule zu schicken, um grundlegende Fähigkeiten zu erlernen, verbessert das Post-Training das Modell um Fähigkeiten, die für die vorgesehene Aufgabe anwendbar sind. Ein LLM könnte beispielsweise nachtrainiert werden, um eine Aufgabe wie eine Stimmungsanalyse oder Übersetzung zu bewältigen – oder den Jargon eines bestimmten Fachgebiets wie Gesundheitswesen oder Recht zu verstehen.
Das Gesetz der Skalierung beim Nachtrainieren geht davon aus, dass die Leistung eines vortrainierten Modells mithilfe von Techniken wie Feinabstimmung, Zuschnitten, Quantisierung, Destillation, bestärkendem Lernen und Augmentation synthetischer Daten weiter verbessert werden kann – in puncto Recheneffizienz, Genauigkeit oder Domänenspezifität.
- Für die Feinabstimmung werden zusätzliche Trainingsdaten verwendet, um ein KI-Modell für bestimmte Bereiche und Anwendungen zuzuschneiden. Dies kann mit den internen Datensätzen eines Unternehmens oder mit Paaren von Eingaben und Ausgaben von Beispielmodellen erfolgen.
- Für die Destillation sind zwei KI-Modelle erforderlich: ein großes, komplexes Lehrermodell und ein leichtes Schülermodell. Bei der gängigsten Destillationstechnik, der Offline-Destillation, lernt das Schülermodell, die Ergebnisse eines vortrainierten Lehrermodells nachzuahmen.
- Bestärkendes Lernen ist eine Technik des maschinellen Lernens, die ein Belohnungsmodell verwendet, um einen Agenten zu trainieren, damit er Entscheidungen trifft, die an einem bestimmten Anwendungsfall ausgerichtet sind. Der Agent zielt darauf ab, Entscheidungen zu treffen, die die kumulativen Belohnungen im Laufe der Zeit maximieren, wenn er mit einer Umgebung interagiert. Beispielsweise ein Chatbot-LLM, das durch positive Reaktionen der Benutzer wie „Daumen hoch“ verstärkt wird. Diese Technik wird als bestärkendes Lernen mit menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF) bezeichnet. Eine weitere, neuere Technik, das bestärkende Lernen durch KI-Feedback (Reinforcement Learning from AI Feedback, RLAIF), nutzt stattdessen das Feedback von KI-Modellen, um den Lernprozess zu leiten und das Nachtrainieren zu optimieren.
- Best-of-n-Sampling generiert mehrere Ausgaben aus einem Sprachmodell und wählt die Ausgabe mit der höchsten Belohnungsbewertung basierend auf einem Belohnungsmodell aus. Es wird häufig verwendet, um die Ausgaben einer KI zu verbessern, ohne Modellparameter zu ändern, und bietet eine Alternative zur Feinabstimmung mit bestärkendem Lernen.
- Suchmethoden untersuchen eine Reihe potenzieller Entscheidungswege, bevor ein endgültiges Ergebnis ausgewählt wird. Diese Post-Training-Technik kann die Reaktionen des Modells iterativ verbessern.
Zur Unterstützung des Nachtrainierens können Entwickler synthetische Daten verwenden, um ihren optimierten Datensatz zu erweitern oder zu ergänzen. Die Ergänzung realer Datensätze mit KI-generierten Daten kann dazu beitragen, dass Modelle ihre Fähigkeit verbessern, Randfälle zu bewältigen, die in den ursprünglichen Trainingsdaten unterrepräsentiert sind oder fehlen.

Was ist Post-Training-Skalierung?
LLMs generieren schnelle Antworten auf Prompts. Dieser Prozess eignet sich zwar gut, um die richtigen Antworten auf einfache Fragen zu erhalten, funktioniert jedoch möglicherweise nicht so gut, wenn ein Benutzer komplexe Abfragen stellt. Die Beantwortung komplexer Fragen – eine wesentliche Funktion für agentenbasierte KI-Workloads – setzt voraus, dass das LLM die Frage gründlich analysiert, bevor es eine Antwort gibt.
Das funktioniert ähnlich wie die meisten Menschen: Wenn sie gebeten werden, zwei plus zwei zu addieren, geben sie eine sofortige Antwort, ohne die Grundlagen der Addition oder der Ganzzahlen abrufen zu müssen. Wird eine Person jedoch spontan gebeten, einen Geschäftsplan zu entwickeln, der die Gewinne eines Unternehmens um 10 % steigern könnte, wird sie wahrscheinlich verschiedene Optionen abwägen und eine Antwort in mehreren Schritten geben.
Die Skalierung der Testzeit, auch als längeres Nachdenken bekannt, findet während der Inferenz statt. Statt herkömmlicher KI-Modelle, die schnell eine Antwort auf einen Prompt generieren, bieten Modelle, die diese Technik verwenden, zusätzlichen Rechenaufwand bei der Inferenz, sodass sie mehrere potenzielle Antworten abwägen können, bevor sie zur besten Antwort gelangen.
Bei Aufgaben wie der Generierung von komplexem, angepasstem Code für Entwickler kann dieser KI-Denkprozess mehrere Minuten oder sogar Stunden dauern. Er kann für herausfordernde Abfragen eine Rechenleistung von mehr als dem Hundertfachen Aufwand erfordern, verglichen mit einem einzigen Inferenzdurchgang in einem herkömmlichen LLM, was höchstwahrscheinlich nicht beim ersten Versuch eine korrekte Antwort auf ein komplexes Problem liefert.
Dieser KI-Reasoning-Prozess kann mehrere Minuten oder sogar Stunden dauern. Er kann für anspruchsvolle Abfragen eine Rechenleistung von mehr als dem Hundertfachen im Vergleich zu einem einzelnen Inferenzdurchgang in einem herkömmlichen LLM erfordern.
Diese Rechenfunktion während der Testzeit ermöglicht es KI-Modellen, verschiedene Lösungen für ein Problem zu erkunden und komplexe Anfragen in mehrere Schritte zu unterteilen – in vielen Fällen zeigen sie den Benutzern ihre Arbeit, während sie schlussfolgern. Studien haben ergeben, dass die Skalierung der Testzeiten zu qualitativ hochwertigeren Antworten führt, wenn KI-Modelle offene Prompts erhalten, die mehrere Denk- und Planungsschritte erfordern.
Die Methodik für die Testzeit-Berechnung bietet viele Ansätze, darunter:
- Kettenartige Denkanstöße: Aufschlüsselung komplexer Probleme in eine Reihe einfacher Schritte.
- Sampling mit Mehrheitsabstimmung: Generieren mehrerer Antworten auf denselben Prompt und anschließend Auswahl der am häufigsten wiederkehrenden Antwort als Endergebnis.
- Suche: Erforschung und Bewertung mehrerer Pfade in einer baumartigen Struktur von Antworten.
Post-Training-Methoden wie Best-of-n-Sampling können auch für langes Nachdenken während der Inferenz verwendet werden, um Reaktionen im Abgleich mit menschlichen Präferenzen oder anderen Zielen zu optimieren.

Wie die Skalierung von Testzeiten KI-Denken ermöglicht
Der Aufstieg der Testzeit-Berechnung eröffnet die Fähigkeit der KI, gut begründete, hilfreiche und genauere Antworten auf komplexe, offene Benutzeranfragen zu geben. Diese Funktionen sind für die detaillierten und mehrstufigen Denkaufgaben von autonomer agentenbasierter KI und physischen KI-Anwendungen von entscheidender Bedeutung. In verschiedenen Branchen könnten sie die Effizienz und Produktivität steigern, indem sie Benutzern hochleistungsfähige Assistenten zur Beschleunigung ihrer Arbeit zur Verfügung stellen.
Im Gesundheitswesen könnten Modelle die Skalierung zur Testzeit nutzen, um riesige Datenmengen zu analysieren und abzuleiten, wie eine Krankheit fortschreitet, sowie potenzielle Komplikationen vorherzusagen, die sich aus neuen Behandlungen ergeben könnten, die auf der chemischen Struktur eines Arzneimittelmoleküls basieren. Oder sie könnten eine Datenbank klinischer Studien durchsuchen, um Optionen vorzuschlagen, die dem Krankheitsprofil einer Person entsprechen, und ihren Argumentationsprozess über die Vor- und Nachteile verschiedener Studien darlegen.
Im Einzelhandel und in der Lieferkettenlogistik kann langfristiges Denken bei der komplexen Entscheidungsfindung helfen, die erforderlich ist, um kurzfristige betriebliche Herausforderungen und langfristige strategische Ziele zu bewältigen. Reasoning-Techniken können Unternehmen helfen, Risiken zu reduzieren und Skalierbarkeitsherausforderungen zu bewältigen, indem sie mehrere Szenarien gleichzeitig vorhersagen und bewerten. Dies könnte eine genauere Bedarfsprognose, optimierte Reiserouten in der Lieferkette und Beschaffungsentscheidungen ermöglichen, die mit den Nachhaltigkeitsinitiativen eines Unternehmens übereinstimmen.
Für globale Unternehmen könnte diese Technik angewendet werden, um detaillierte Geschäftspläne zu erstellen, komplexen Programmcode zum Debuggen von Software zu generieren oder Fahrtrouten für Lieferwagen, Lagerroboter und Robotertaxis zu optimieren.
KI-Reasoning-Modelle entwickeln sich rasant weiter. OpenAI o1-mini und o3-mini, DeepSeek R1 und Google DeepMind Gemini 2.0 Flash Thinking wurden in den letzten Wochen eingeführt. Es wird erwartet, dass in Kürze weitere Modelle folgen werden.
Modelle wie diese erfordern erheblich mehr Rechenleistung für das Reasoning bei der Inferenz und generieren korrekte Antworten auf komplexe Fragen. Das bedeutet, dass Unternehmen ihre beschleunigten Rechenressourcen skalieren müssen, um die nächste Generation von KI-Reasoning-Tools bereitzustellen, die komplexe Problemlösung, Programmierung und mehrstufige Planung unterstützen können.
Erfahren Sie mehr über die Vorteile von NVIDIA KI für beschleunigte Inferenz.