
Offene Modelle treiben eine neue Welle der gerätebasierten KI voran und dehnen Innovationen über die Cloud hinaus auf alltägliche Geräte aus. Mit der Weiterentwicklung dieser Modelle hängt ihr Nutzen zunehmend vom Zugang zu lokalen Echtzeitdaten ab, die es ermöglichen, aussagekräftige Erkenntnisse in konkrete Maßnahmen umzusetzen.
Die neuesten Ergänzungen von Google zur Gemma 4-Familie wurden für diese Veränderung entwickelt und stellen eine Klasse von kleinen, schnellen und omnifähigen Modellen vor, die für eine effiziente lokale Ausführung auf einer Vielzahl von Geräten entwickelt wurden.
Google und NVIDIA haben gemeinsam Gemma 4 für NVIDIA-GPUs optimiert und eine effiziente Leistung in einer Reihe von Systemen ermöglicht – von Rechenzentrumsbereitstellungen bis hin zu NVIDIA RTX-gestützten PCs und Workstations, dem persönlichen KI-Supercomputer NVIDIA DGX Spark und NVIDIA Jetson Orin Nano Edge-KI-Modulen.
Gemma 4: Kompakte Modelle, die für NVIDIA-GPUs optimiert sind
Die neuesten Ergänzungen der Gemma 4-Familie offener Modelle – E2B, E4B, 26B und 31B – sind für die effiziente Bereitstellung von Edge-Geräten bis hin zu leistungsstarken GPUs entwickelt.
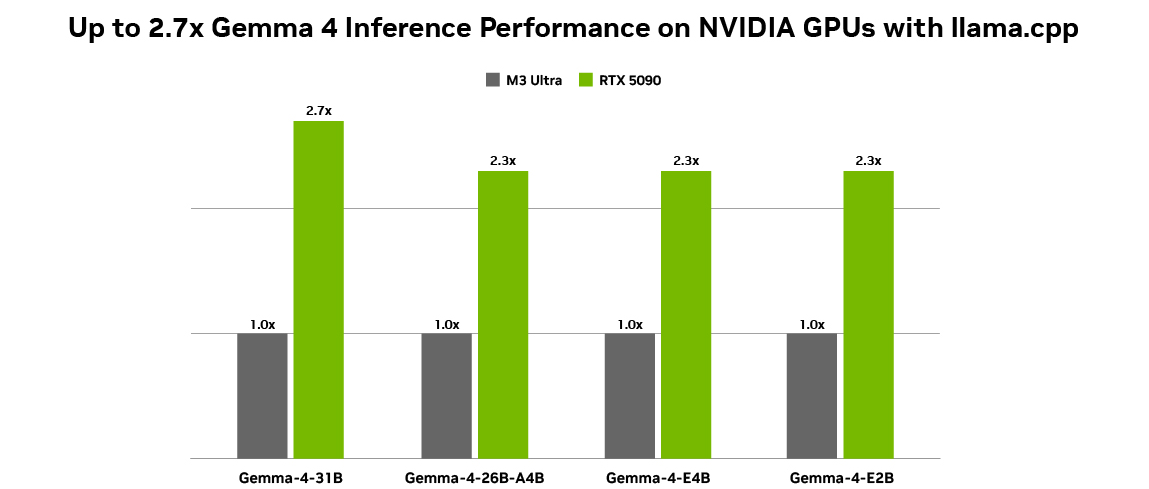
Diese neue Generation von kompakten Modellen unterstützt eine Reihe von Aufgaben, darunter:
- Reasoning: Hervorragende Leistung bei komplexen Problemlösungsaufgaben.
- Coding: Code-Generierung und Debugging für Entwickler-Workflows.
- Agenten: Native Unterstützung für die strukturierte Tool-Nutzung (Funktionsaufrufe).
- Vision-, Video- und Audiofunktionen: Ermöglicht umfangreiche multimodale Interaktionen für Objekterkennung, automatisierte Spracherkennung und Dokumenten- oder Video-Intelligenz.
- Verschachtelte multimodale Eingabe: Mischen Sie Text und Bilder in beliebiger Reihenfolge innerhalb eines einzigen Prompts.
- Mehrsprachig: Sofortige Unterstützung für über 35 Sprachen, vortrainiert in über 140 Sprachen.
Die E2B- und E4B-Modelle sind für ultraeffiziente Inferenz mit geringer Latenz am Edge entwickelt und können mit nahezu Null Latenz auf vielen Geräten, einschließlich Jetson Nano-Modulen, vollständig offline ausgeführt werden.
Die Modelle 26B und 31B sind für leistungsstarkes Reasoning und entwicklerzentrierte Workflows entwickelt worden und eignen sich daher gut für agentische KI. Diese Modelle sind für modernstes, zugängliches Reasoning optimiert und werden effizient auf NVIDIA RTX GPUs und DGX Spark ausgeführt – und unterstützen Entwicklungsumgebungen, Programmierassistenten und agentengesteuerte Workflows.
Da lokale agentische KI weiter an Dynamik gewinnt, ermöglichen Anwendungen wie OpenClaw den Einsatz von Always-On-KI-Assistenten auf RTX PCs, Workstations und DGX Spark. Die neuesten Gemma 4-Modelle sind mit OpenClaw kompatibel, sodass Nutzer leistungsfähige lokale Agenten entwickeln können, die Kontext aus persönlichen Dateien, Anwendungen und Workflows ziehen, um Aufgaben zu automatisieren. Erfahren Sie, wie Sie OpenClaw kostenlos auf RTX-GPUs und DGX Spark oder mit dem DGX Spark OpenClaw Playbook ausführen können.
Sehen Sie sich den Google DeepMind-Ankündigungsblog an, um mehr über die neuesten Ergänzungen der Gemma 4-Familie
zu erfahren.
Erste Schritte: Gemma 4 auf RTX-GPUs und DGX Spark
NVIDIA hat mit Ollama und llama.cpp zusammengearbeitet, um die beste lokale Bereitstellungserfahrung für jedes der Gemma 4-Modelle zu bieten.
Um Gemma 4 lokal zu nutzen, können Benutzer Ollama herunterladen, um Gemma 4-Modelle auszuführen, oder llama.cpp installieren und es mit dem Gemma 4 GGUF Hugging Face Checkpoint kombinieren. Darüber hinaus bietet Unsloth Day-One-Support mit optimierten und quantisierten Modellen für eine effiziente lokale Feinabstimmung und Bereitstellung über Unsloth Studio. Beginnen Sie noch heute damit, Gemma 4 in Unsloth Studio auszuführen und zu optimieren.
Die Ausführung offener Modelle wie die Gemma 4-Familie auf NVIDIA GPUs erzielt eine optimale Leistung, da NVIDIA Tensor-Recheneinheiten KI-Inferenz-Workloads beschleunigen und einen höheren Durchsatz und eine geringere Latenz für die lokale Ausführung bieten. Darüber hinaus gewährleistet der CUDA-Software-Stack eine umfassende Kompatibilität mit führenden Frameworks und Tools, sodass neue Modelle vom ersten Tag an effizient ausgeführt werden können.
Durch diese Kombination können offene Modelle wie Gemma 4 über eine Vielzahl von Systemen hinweg skaliert werden – von Jetson Orin Nano am Edge bis hin zu RTX PCs, Workstations und DGX Spark, ohne dass umfangreiche Optimierungen erforderlich sind.
Im technischen Blog von NVIDIA finden Sie weitere Details zu den ersten Schritten mit Gemma 4 auf NVIDIA-GPUs und mehr über die Arbeiten von NVIDIA an offenen Modellen.
#ICYMI: Die neuesten Updates für RTX KI-PCs
✨ Lesen Sie die RTX AI Garage-Blogs über eine Vielzahl von Ankündigungen zu agentischer KI von der NVIDIA GTC, wie beispielsweise neue offene Modelle für lokale Agenten. Zu diesen Modellen gehören NVIDIA Nemotron 3 Nano 4B und Nemotron 3 Super 120B sowie Optimierungen für Qwen 3.5 und Mistral Small 4.
NVIDIA hat kürzlich NVIDIA NemoClaw vorgestellt, einen Open-Source-Stack, der das OpenClaw-Nutzererlebnis auf NVIDIA-Geräten durch Erhöhung der Sicherheit und Unterstützung lokaler Modelle optimiert.
🚀 Accomplish.ai kündigte Accomplish FREE an, eine kostenlose Version seines Open-Source-Desktop-KI-Agenten mit integrierten Modellen. Es nutzt NVIDIA-GPUs, um Open-Weight-Modelle lokal auszuführen, während ein hybrider Router Workloads dynamisch zwischen lokaler RTX-Hardware und der Cloud verteilt – dies ermöglicht eine schnelle, private Ausführung ohne Konfigurationaufwand und ohne, dass ein API-Key erforderlich ist.
Melden Sie sich bei NVIDIA AI PC auf Facebook, Instagram, TikTok und X an und bleiben Sie auf dem Laufenden, indem Sie den RTX AI PC-Newsletter abonnieren.