
Anmerkung der Redaktion: Dieser Beitrag ist Teil von Think SMART, einer Serie, die sich darauf konzentriert, wie führende KI-Dienstanbieter, Entwickler und Unternehmen ihre Inferenzleistung und ihre Investitionsrendite mit den neuesten Fortschritten der Full-Stack-Inferenzplattform von NVIDIA steigern können.
NVIDIA Blackwell liefert die höchste Leistung und Effizienz und die niedrigsten Gesamtbetriebskosten für jedes getestete Modell und jeden Anwendungsfall im kürzlich durchgeführten unabhängigen SemiAnalysis InferenceMAX v1 Benchmark.
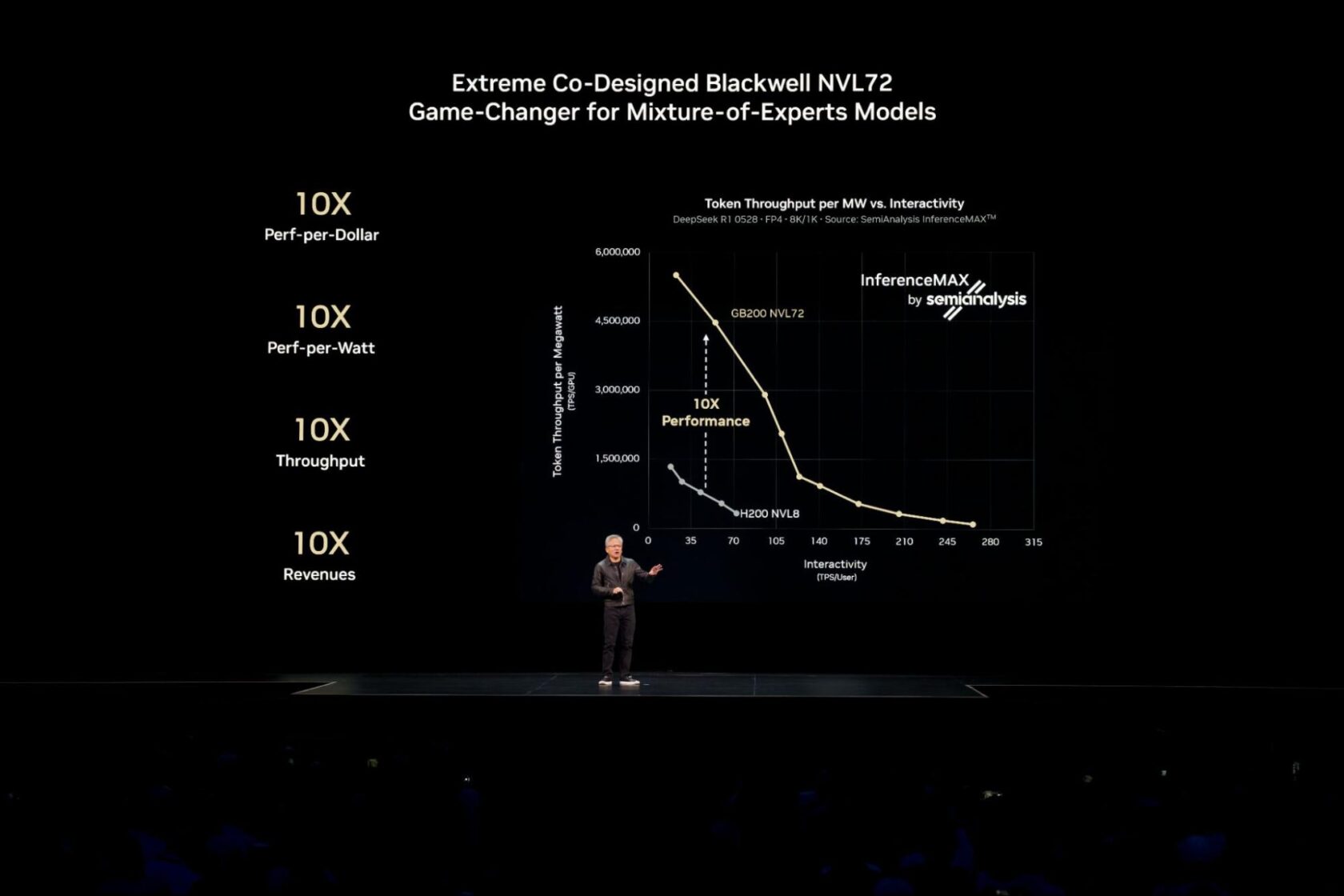
Um diese branchenführende Leistung für die komplexesten KI-Modelle der heutigen Zeit, wie beispielsweise groß angelegte Mixture-of-Experts (MoE)-Modelle, zu erzielen, ist die Verteilung (oder Disaggregation) der Inferenz über mehrere Server (Knoten) hinweg erforderlich, um Millionen gleichzeitiger Benutzer zu bedienen und schnellere Reaktionen zu liefern.
Die NVIDIA Dynamo Softwareplattform schaltet diese leistungsstarken Multi-Node-Funktionen für die Produktion frei, sodass Unternehmen dieselbe Benchmark-Siegerleistung und Effizienz in ihren bestehenden Cloud-Umgebungen erzielen können. Lesen Sie weiter, um zu erfahren, wie der Übergang zur Inferenz mit mehreren Knoten die Leistung antreibt und wie Cloud-Plattformen diese Technologie in die Praxis umsetzen.
Nutzung der disaggregierten Inferenz für optimierte Leistung
Für KI-Modelle, die auf eine einzelne GPU oder Server passen, führen Entwickler oft viele identische Replikationen des Modells parallel über mehrere Knoten hinweg aus, um einen hohen Durchsatz zu erzielen. In einem kürzlich erschienenen Papier zeigte Russ Fellows, Chefanalyst bei Signal65, dass mit diesem Ansatz ein branchenweit erster Rekorddurchsatz von 1,1 Millionen Token pro Sekunde mit 72 NVIDIA Blackwell Ultra GPUs erzielt wurde.
Bei der Skalierung der KI-Modelle, um viele gleichzeitige Nutzer in Echtzeit zu bedienen, oder bei der Verwaltung anspruchsvoller Workloads mit langen Eingabesequenzen werden durch die Verwendung einer Technik namens disaggregiertes Serving weitere Leistungs- und Effizienzgewinne freigeschaltet.
Das Bedienen von KI-Modellen umfasst zwei Phasen: Verarbeitung der Eingabeaufforderung (Prefill) und Generierung der Ausgabe (Decode). Traditionell laufen beide Phasen auf denselben GPUs, was Ineffizienzen und Ressourcenengpässe verursachen kann.
Disaggregiertes Serving löst dies, indem diese Aufgaben intelligent auf unabhängig optimierte GPUs verteilt werden.
Dieser Ansatz stellt sicher, dass jeder Teil des Workloads mit den am besten geeigneten Optimierungstechniken ausgeführt wird, um die Gesamtleistung zu maximieren. Für heutige große KI-Argumentations– und MoE-Modelle wie DeepSeek-R1 ist das disaggregierte Serving unerlässlich.
NVIDIA Dynamo bringt Funktionen wie das disaggregierte Serving mühelos in den Produktionsbetrieb.
Es liefert bereits einen Mehrwert.
Baseten hat beispielsweise NVIDIA Dynamo genutzt, um die Inferenz für Langkontext-Code-Generierung um das Doppelte zu beschleunigen und den Durchsatz um das 1,6-Fache zu erhöhen, ohne inkrementelle Hardwarekosten. Solche softwaregesteuerten Leistungssteigerungen ermöglichen es KI-Anbietern, die Kosten für die Herstellung von Intelligenz erheblich zu senken.
Skalierung der disaggregierten Inferenz in der Cloud
Ähnlich wie beim KI-Training im großen Maßstab ist Kubernetes – der Branchenstandard für containerisiertes Anwendungsmanagement – gut positioniert, um disaggregiertes Serving über Dutzende oder sogar Hunderte von Knoten für KI-Bereitstellungen im Unternehmensmaßstab zu skalieren.
Da NVIDIA Dynamo jetzt in verwaltete Kubernetes-Systeme mit mehreren Knoten integriert ist, können Kunden die Inferenz über NVIDIA Blackwell-Knoten mit der Leistung, Flexibilität und Zuverlässigkeit skalieren, die Unternehmens-KI-Bereitstellungen verlangen.
- Amazon Web Services beschleunigt die generative KI-Inferenz für seine Kunden mit NVIDIA Dynamo und der Integration in Amazon EKS.
- Google Cloud bringt das Dynamo Rezept zur Optimierung der Inferenz großer Sprachmodelle (LLM) im Unternehmensmaßstab auf seine KI-Hypercomputer.
- Microsoft Azure ermöglicht die Multi-Node-LLM-Inferenz mit NVIDIA Dynamo und ND GB200-v6 GPUs auf dem Azure Kubernetes Service.
- Oracle Cloud Infrastructure (OCI) ermöglicht die Inferenz mit mehreren Knoten mit OCI Superclusters und NVIDIA Dynamo.
Der Trend hin zu groß angelegter, Multi-Knoten-Inferenz geht über Hyperscaler hinaus.
Nebius entwirft beispielsweise seine Cloud, um Inferenz-Workloads im großen Maßstab zu bedienen, basierend auf einer beschleunigten Recheninfrastruktur von NVIDIA und in Zusammenarbeit mit NVIDIA Dynamo als Ökosystempartner.
Vereinfachung der Inferenz auf Kubernetes mit NVIDIA Grove in NVIDIA Dynamo
Disaggregierte KI-Inferenz erfordert die Koordination eines Bündles spezialisierter Komponenten – Prefill, Decode, Routing und mehr – mit jeweils unterschiedlichen Bedürfnissen. Die Herausforderung für Kubernetes besteht nicht länger darin, mehr parallele Kopien eines Modells auszuführen, sondern vielmehr darin, diese unterschiedlichen Komponenten als ein kohärentes Hochleistungssystem meisterhaft zu koordinieren.
NVIDIA Grove, eine Anwendungsprogrammierschnittstelle, die jetzt innerhalb von NVIDIA Dynamo verfügbar ist, ermöglicht es Benutzern, eine einzelne, hochrangige Spezifikation bereitzustellen, die ihr gesamtes Inferenzsystem beschreibt.
Zum Beispiel könnte ein Benutzer in dieser einzigen Spezifikation einfach seine Anforderungen angeben: „Ich brauche drei GPU-Knoten für das Prefill und sechs GPU-Knoten für das Decode, und ich benötige, dass alle Knoten für eine einzelne Modellreplikation auf derselben Hochgeschwindigkeits-Verbindungsleitung platziert werden.“
Ausgehend von dieser Spezifikation übernimmt Grove automatisch die gesamte komplizierte Koordination: Skalierung verwandter Komponenten unter Beibehaltung korrekter Verhältnisse und Abhängigkeiten, Starten in der richtigen Reihenfolge und strategische Platzierung über den gesamten Cluster hinweg für schnelle, effiziente Kommunikation. Erfahren Sie in diesem technischen Deep Dive mehr darüber, wie Sie mit NVIDIA Grove starten können.
Da KI-Inferenz zunehmend verteilt wird, vereinfacht die Kombination von Kubernetes und NVIDIA Dynamo mit NVIDIA Grove die Art und Weise, wie Entwickler intelligente Anwendungen entwickeln und skalieren.
Probieren Sie die KI-Simulation im Maßstab, um zu sehen, wie sich Hardware- und Bereitstellungsentscheidungen auf Leistung, Effizienz und Benutzererfahrung auswirken. Um tiefer in das disaggregierte Serving einzutauchen und zu erfahren, wie Dynamo und NVIDIA GB200 NVL72-Systeme zusammenarbeiten, um die Inferenzleistung zu steigern, lesen Sie diesen technischen Blog.
Für monatliche Updates melden Sie sich für den NVIDIA Think SMART Newsletter an.