
- NVIDIA Blackwell hat die neuen SemiAnalysis InferenceMAX v1-Benchmarks dominiert und dabei die höchste Leistung und beste Gesamteffizienz erzielt.
- InferenceMax v1 ist der erste unabhängige Benchmark, der die Gesamtkosten für Rechenleistung über verschiedene Modelle über reale Szenarien hinweg misst.
- Beste Kapitalrendite: NVIDIA GB200 NVL72 bietet eine unübertroffene Wirtschaftlichkeit für KI-Fabriken – eine Investition von 5 Millionen US-Dollar generiert 75 Millionen US-Dollar an DSR1-Token-Einnahmen, was einer 15-fachen Kapitalrendite entspricht.
- Niedrigste Gesamtbetriebskosten: Mit seinen Softwareoptimierungen erreicht der NVIDIA B200 zwei Cent pro Million Token auf gpt-oss und liefert damit in nur zwei Monaten 5-mal niedrigere Kosten pro Token.
- Bester Durchsatz und beste Interaktivität: NVIDIA B200 setzt mit 60.000 Tokens pro Sekunde pro GPU und 1.000 Tokens pro Sekunde pro Benutzer auf gpt-oss mit dem neuesten NVIDIA TensorRT-LLM-Stack neue Maßstäbe.
Während die KI von One-Shot-Antworten auf komplexes Reasoning übergeht, explodiert die Nachfrage nach Inferenz – und und die damit verbundenen Kosten – geradezu.
Die neuen unabhängigen InferenceMAX v1-Benchmarks sind die ersten, die die Gesamtkosten für das Computing in realen Szenarien messen. Die Ergebnisse? Die Flaggschiff-Blackwell-Plattform von NVIDIA hat das Feld erobert und bietet unübertroffene Leistung und höchste Gesamteffizienz für KI-Fabriken.
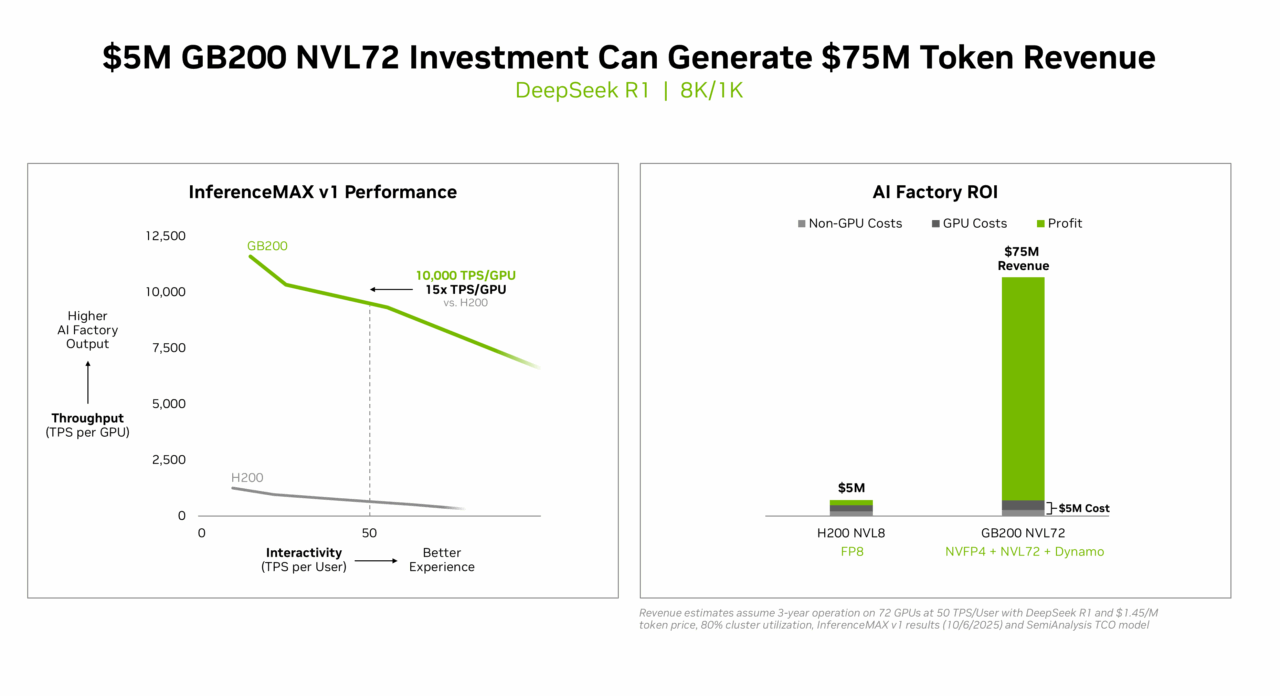
Eine Investition in Höhe von 5 Millionen US-Dollar in ein GB200 NVL72-System kann Token-Einnahmen in Höhe von 75 Millionen US-Dollar generieren. Das entspricht einer 15-fachen Kapitalrendite ROI – die neue Wirtschaftlichkeit der Inferenz.
„Inferenz ist der Bereich, in dem KI jeden Tag Wert schafft“, sagte Ian Buck, Vizepräsident für Hyperscale und HPC bei NVIDIA. „Diese Ergebnisse zeigen, dass der Full-Stack-Ansatz von NVIDIA Kunden die Leistung und Effizienz bietet, die sie benötigen, um KI in großem Maßstab bereitzustellen.“
InferenceMAX v1 aufrufen
InferenceMAX v1, ein neuer Benchmark von SemiAnalysis, der am Montag veröffentlicht wurde, ist der neueste Benchmark, der die führende Rolle von Blackwell im Bereich Inferenz hervorhebt. Es führt populäre Modelle auf führenden Plattformen aus, misst die Leistung für eine Vielzahl von Anwendungsfällen und veröffentlicht Ergebnisse, die jeder verifizieren kann.
Warum sind Benchmarks wie dieser wichtig?
Weil es bei moderner KI nicht nur um Rohgeschwindigkeit geht, sondern auch um Effizienz und Wirtschaftlichkeit in großem Maßstab. Da Modelle von One-Shot-Antworten zu mehrstufigem Reasoning und Tool-Nutzung übergehen, generieren sie weitaus mehr Token pro Abfrage und erhöhen die Rechenanforderungen erheblich.
Die Open-Source-Kooperationen von NVIDIA mit OpenAI (gpt-oss 120B), Meta (Llama 3 70B) und DeepSeek AI (DeepSeek R1) zeigen, wie Community-entwickelte Modelle hochmodernes Reasoning und Effizienz fördern.
In der Partnerschaft mit diesen führenden Modellentwicklern und der Open-Source-Community stellt NVIDIA sicher, dass die neuesten Modelle für die weltweit größte KI-Inferenzinfrastruktur optimiert sind. Diese Bemühungen spiegeln ein breiteres Engagement für offene Ökosysteme wider, in denen gemeinsame Innovation den Fortschritt für alle beschleunigt.
Enge Partnerschaften mit den Communities FlashInfer, SGLang und vLLM ermöglichen gemeinsam entwickelte Kernel- und Laufzeitverbesserungen, die diese Modelle in großem Maßstab unterstützen.
Kontinuierliche Software-Innovation unterstützt Blackwell-Inferenz
NVIDIA verbessert kontinuierlich die Leistung durch Hardware- und Software-Co-Design-Optimierungen. Die anfängliche gpt-oss-120b-Leistung auf Blackwell B200 mit TensorRT-LLM war marktführend, aber die NVIDIA-Teams und die Community haben TensorRT-LLM für Open-Source-LLMs erheblich optimiert.
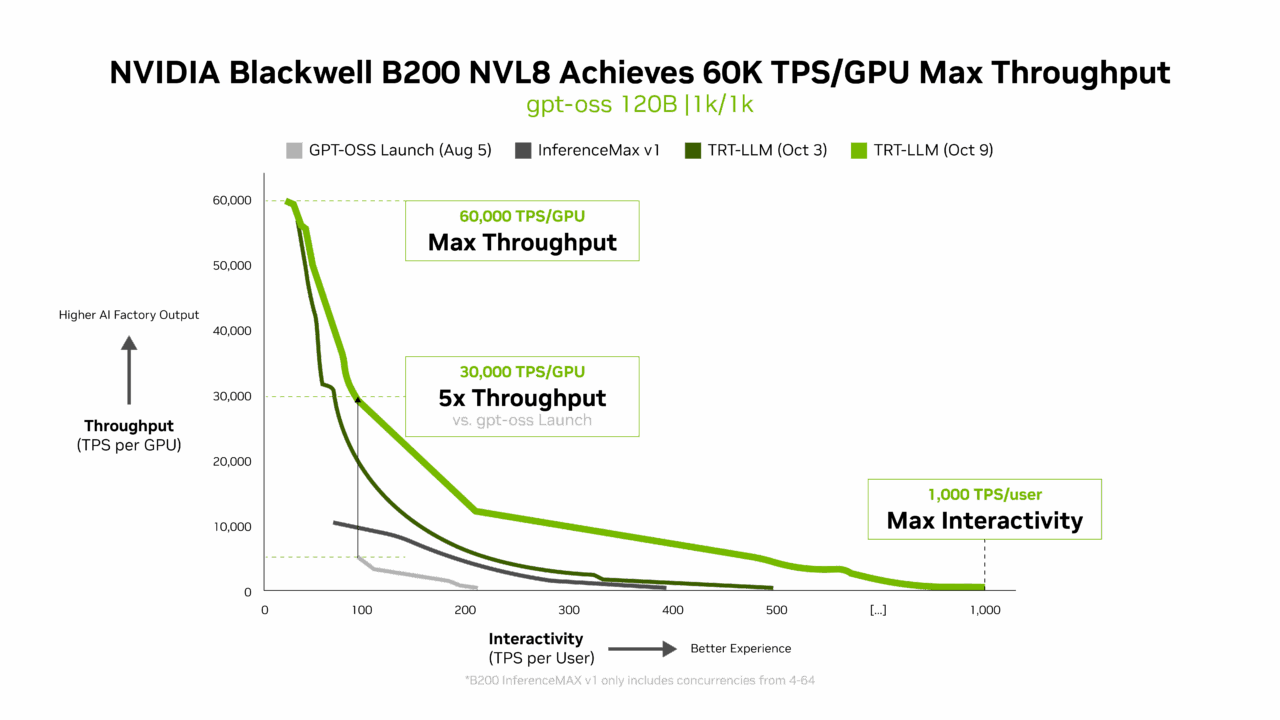
Die neueste TensorRT-LLM 1.0-Version von NVIDIA ist ein wichtiger Durchbruch, um große KI-Modelle für alle schneller und reaktionsschneller zu machen.
Durch fortschrittliche Parallelisierungstechniken nutzt es B200 und die bidirektionale Bandbreite von 1.800 GB/s seines NVLink Switch, um die Leistung des gpt-oss-120b-Modells erheblich zu verbessern – von nur 6.000 Token pro GPU bei der Einführung auf 60.000 Token heute, was eine 10-fache Steigerung in nur zwei Monaten bedeutet.
Aber die Innovation hört dort nicht auf. Das neu veröffentlichte gpt-oss-120b-Eagle3-Modell führt die spekulative Dekodierung ein, eine clevere Methode, die mehrere Token gleichzeitig vorhersagt. Dies reduziert Verzögerungen und liefert noch schnellere Ergebnisse, wodurch sich der Durchsatz auf 100 TPS pro Benutzer verdreifacht – und die Geschwindigkeiten pro GPU von 10.000 auf 30.000 Token erhöht.
Dank dieser Fortschritte ist die Ausführung riesiger KI-Modelle jetzt viel kostengünstiger und zugänglicher und unterstützt Apps und Dienste der nächsten Generation, die auf schnelle KI-Antworten angewiesen sind. Für komplexe KI-Modelle wie Llama 3.3 70B, die aufgrund ihrer großen Parameteranzahl und der Tatsache, dass alle Parameter während der Inferenz gleichzeitig genutzt werden, erhebliche Rechenressourcen erfordern, setzt NVIDIA Blackwell B200 einen neuen Leistungsstandard in InferenceMAX v1-Benchmarks.
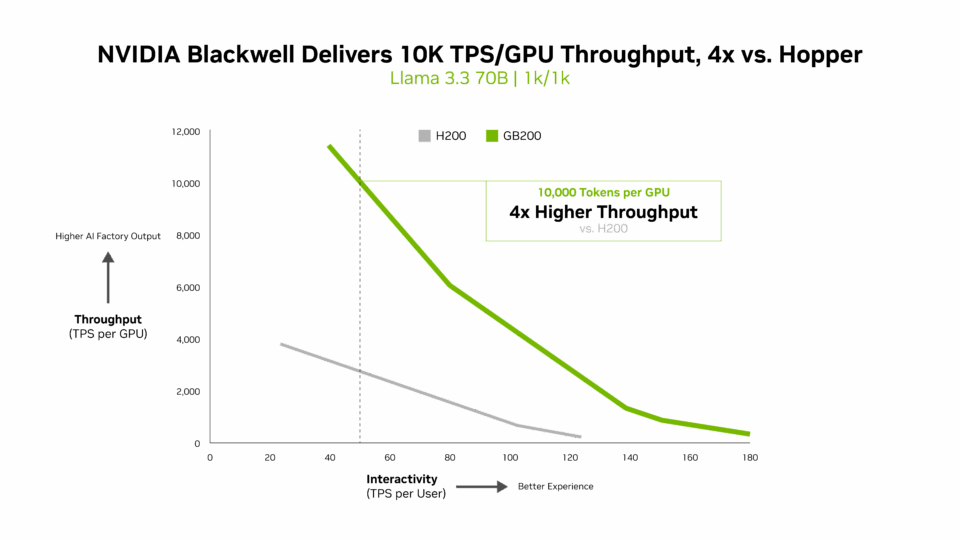
Blackwell bietet über 10.000 TPS pro GPU bei 50 TPS pro Benutzerinteraktivität – ein 4-mal höherer Durchsatz pro GPU im Vergleich zu Hopper H200.
Leistungseffizienz schafft Mehrwert
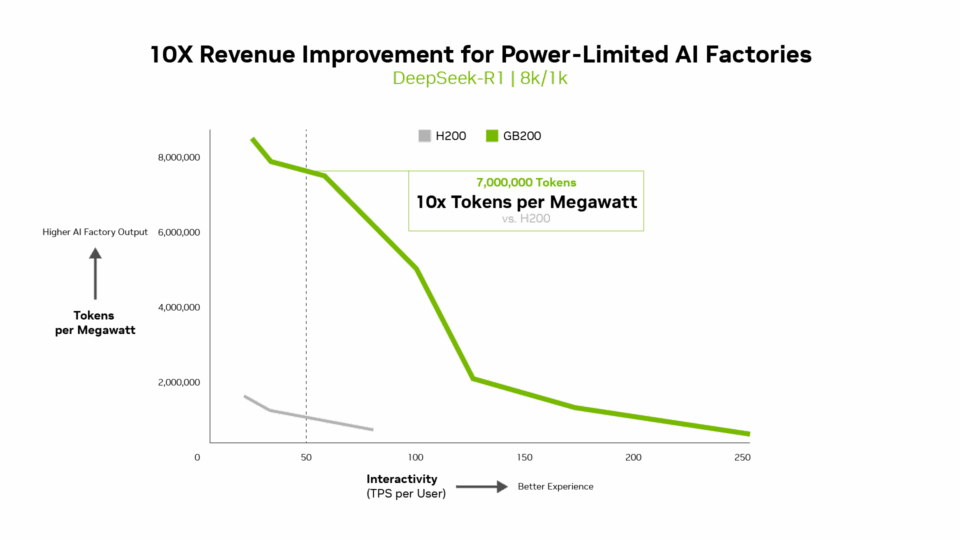
Kennzahlen wie Token pro Watt, Kosten pro Million Token und TPS/Benutzer sind genauso wichtig wie der Durchsatz. Tatsächlich liefert Blackwell für KI-Fabriken mit begrenzter Leistung einen zehnmal höheren Durchsatz pro Megawatt im Vergleich zur vorherigen Generation, was zu höheren Token-Einnahmen führt.
Die Kosten pro Token sind entscheidend für die Bewertung der Effizienz von KI-Modellen und wirken sich direkt auf die Betriebskosten aus. Die Blackwell-Architektur hat die Kosten pro Million Token im Vergleich zu der vorherigen Generation um das 15-Fache gesenkt, was zu erheblichen Einsparungen geführt und eine breitere KI-Bereitstellung und -Innovation gefördert hat.
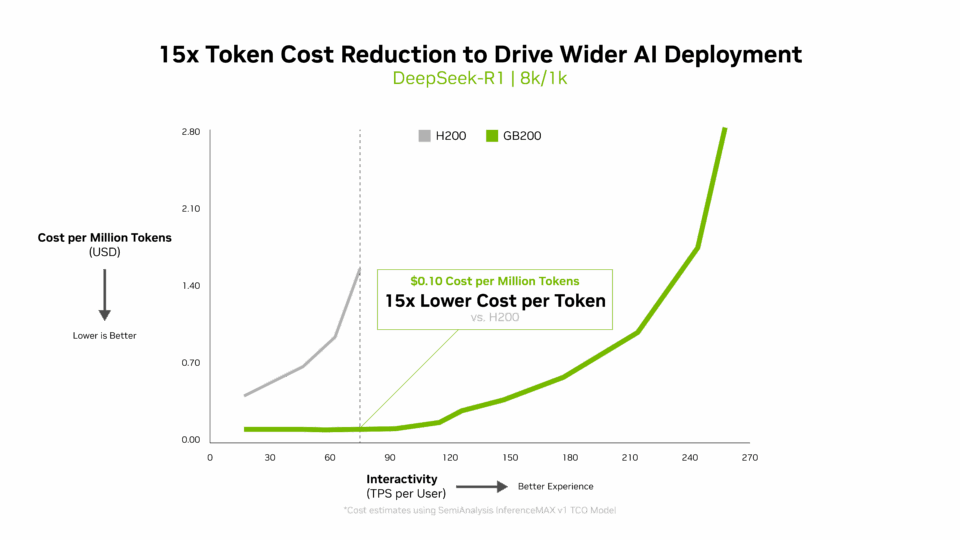
Multi-Dimensionale Leistung
InferenceMAX nutzt die Pareto-Frontier – eine Kurve, die die besten Kompromisse zwischen verschiedenen Faktoren wie Durchsatz und Reaktionsfähigkeit von Rechenzentren darstellt – um die Leistung abzubilden.
Aber es ist mehr als ein Diagramm. Es spiegelt wider, wie NVIDIA Blackwell das gesamte Spektrum der Produktionsprioritäten ausbalanciert: Kosten, Energieeffizienz, Durchsatz und Reaktionsfähigkeit. Dieses Gleichgewicht ermöglicht den höchsten ROI für reale Workloads.
Systeme, die für nur einen Modus oder ein Szenario optimieren, können Spitzenleistung isoliert aufweisen, die Wirtschaftlichkeit lässt sich jedoch nicht skalieren. Das Full-Stack-Design von Blackwell bietet Effizienz und Wert dort, wo es am wichtigsten ist: in der Produktion.
Einen tieferen Einblick in die Entwicklung dieser Kurven – und warum sie für die Gesamtbetriebskosten und die Planung von Service-Level-Vereinbarungen wichtig sind – finden Sie in unserer technischen Analyse mit vollständigen Diagrammen und Methodik.
Wie wird dies ermöglicht?
Die Führungsrolle von Blackwell beruht auf einem extrem integrierten Hardware-Software-Co-Design. Es ist eine Full-Stack-Architektur, die für Geschwindigkeit, Effizienz und Skalierbarkeit ausgelegt ist:
- Zu den Blackwell-Architekturfunktionen gehören:
- NVFP4-Niedrigpräzisionsformat für Effizienz ohne Genauigkeitsverlust
- NVIDIA NVLink der fünften Generation verbindet 72 Blackwell-GPUs, um als eine riesige GPU zu fungieren.
- NVLink Switch ermöglicht eine hohe Parallelität durch fortschrittliche Tensor-, Experten- und datenparallele Aufmerksamkeitsalgorithmen.
- Jährliche Hardware-Kadenz plus kontinuierliche Softwareoptimierung – NVIDIA hat die Blackwell-Leistung seit der Einführung allein durch Software mehr als verdoppelt
- NVIDIA TensorRT-LLM, NVIDIA Dynamo, SGLang und vLLM Open-Source-Inferenz-Frameworks, optimiert für höchste Leistung
- Ein riesiges Ökosystem mit Hunderten Millionen von installierten GPUs, sieben Millionen CUDA-Entwicklern und Beiträgen zu über 1.000 Open-Source-Projekten
Das Gesamtbild
KI verlagert sich von Pilotprojekten zu KI-Fabriken – einer Infrastruktur, die Intelligenz herstellt, indem sie Daten in Echtzeit in Token und Entscheidungen umwandelt.
Offene, häufig aktualisierte Benchmarks helfen Teams, fundierte Plattformentscheidungen zu treffen, Kosten pro Token, Latenz-Service-Level-Vereinbarungen und Auslastung für sich ändernde Workloads zu optimieren.
Das Think SMART-Framework von NVIDIA hilft Unternehmen bei dieser Veränderung und hebt hervor, wie die Full-Stack-Inferenzplattform von NVIDIA einen realen ROI bietet und Leistung in Gewinne umwandelt.