Die NVIDIA Blackwell-Plattform wird von führenden Inferenzanbietern wie Baseten, DeepInfra, Fireworks AI und Together AI genutzt, um die Kosten pro Token um das bis zu 10-Fache zu senken. Jetzt treibt die NVIDIA Blackwell Ultra-Plattform diese Dynamik für agentenbasierte KI weiter voran.
KI-Agenten und Programmierassistenten sorgen für ein explosives Wachstum bei KI-Anfragen im Bereich der Softwareprogrammierung: Laut dem Bericht zum Stand der Inferenz von OpenRouter sind die Anteile von KI-Abfragen im Zusammenhang mit der Softwareprogrammierung von 11 % auf etwa 50 % im letzten Jahr gestiegen. Diese Anwendungen erfordern eine geringe Latenz, um die Reaktionsfähigkeit in Echtzeit in mehrstufigen Arbeitsabläufen und langen Kontexten beim Reasoning für kompletten Codebasen aufrechtzuerhalten.
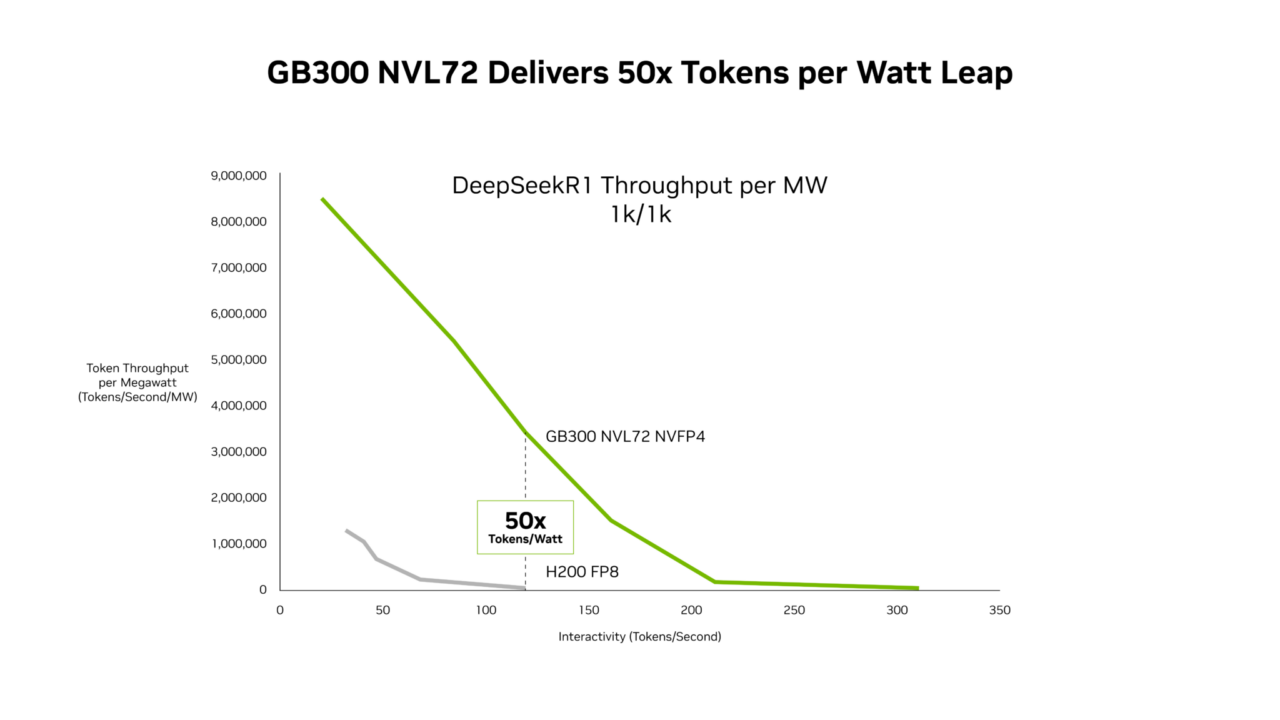
Neue SemiAnalysis InferenceX Leistungsdaten zeigen, dass die Kombination von Software-Optimierungen von NVIDIA und der NVIDIA Blackwell Ultra Plattform der nächsten Generation bahnbrechende Fortschritte an beiden Fronten ermöglicht hat. NVIDIA GB300 NVL72-Systeme bieten jetzt einen bis zu 50-mal höheren Durchsatz pro Megawatt, was zu 35-mal niedrigeren Kosten pro Token im Vergleich zur NVIDIA Hopper-Plattform führt.
Durch Innovationen in den Bereichen Chips, Systemarchitektur und Software beschleunigt das extreme Co-Design von NVIDIA die Leistung in verschiedenen KI-Workloads – von agentischer Programmierung bis hin zu interaktiven Programmierassistenten – und senkt gleichzeitig die Kosten in großem Umfang.

GB300 NVL72 bietet bis zu 50-mal mehr Leistung für Workloads mit geringer Latenz
Aktuelle Analysen von Signal65 zeigen, dass NVIDIA GB200 NVL72 mit extremem Hardware- und Software-Co-Design mehr als 10-mal mehr Token pro Watt liefert, was zu einem Zehntel der Kosten pro Token im Vergleich zur NVIDIA Hopper-Plattform führt. Diese enormen Leistungssteigerungen werden mit der Verbesserung des zugrunde liegenden Stacks noch weiter ausgebaut.
Kontinuierliche Optimierungen der NVIDIA TensorRT-LLM-, NVIDIA Dynamo-, Mooncake- und SGLang-Teams steigern den Durchsatz von Blackwell NVL72 für MoE-Inferenz (Mixture-of-Experts) für alle Latenzziele weiterhin erheblich. So erzielten beispielsweise die Verbesserungen in der NVIDIA TensorRT-LLM Bibliothek auf GB200 bei Workloads mit geringer Latenz im Vergleich zu vor nur vier Monaten eine bis zu fünfmal höhere Leistung.
- Leistungsstärkere GPU-Kernel, die für Effizienz und geringe Latenz optimiert sind, tragen dazu bei, die immensen Rechenkapazitäten von Blackwell optimal zu nutzen und den Durchsatz zu steigern.
- NVIDIA NVLink Symmetric Memory ermöglicht einen direkten GPU-zu-GPU-Speicherzugriff für effizientere Kommunikation.
- Der programmgesteuerte abhängige Start minimiert Leerlaufzeiten, indem die Einrichtungsphase des nächsten Kernels bereits gestartet wird, bevor die vorherige abgeschlossen ist.
Ausgehend von diesen softwaretechnischen Fortschritten setzt GB300 NVL72 – der mit der Blackwell Ultra-GPU ausgestattet ist – neue Maßstäbe beim Durchsatz pro Megawatt und erreicht im Vergleich zur Hopper Plattform das 50-Fache.
Dieser Leistungsgewinn schlägt sich in einer überragenden Wirtschaftlichkeit nieder, da NVIDIA GB300 die Kosten im Vergleich zur Hopper Plattform über das gesamte Latenzspektrum hinweg senkt. Die deutlichste Reduzierung tritt bei geringer Latenz auf, wo agentische Anwendungen arbeiten: bis zu 35-mal geringere Kosten pro Million Token im Vergleich zur Hopper-Plattform.
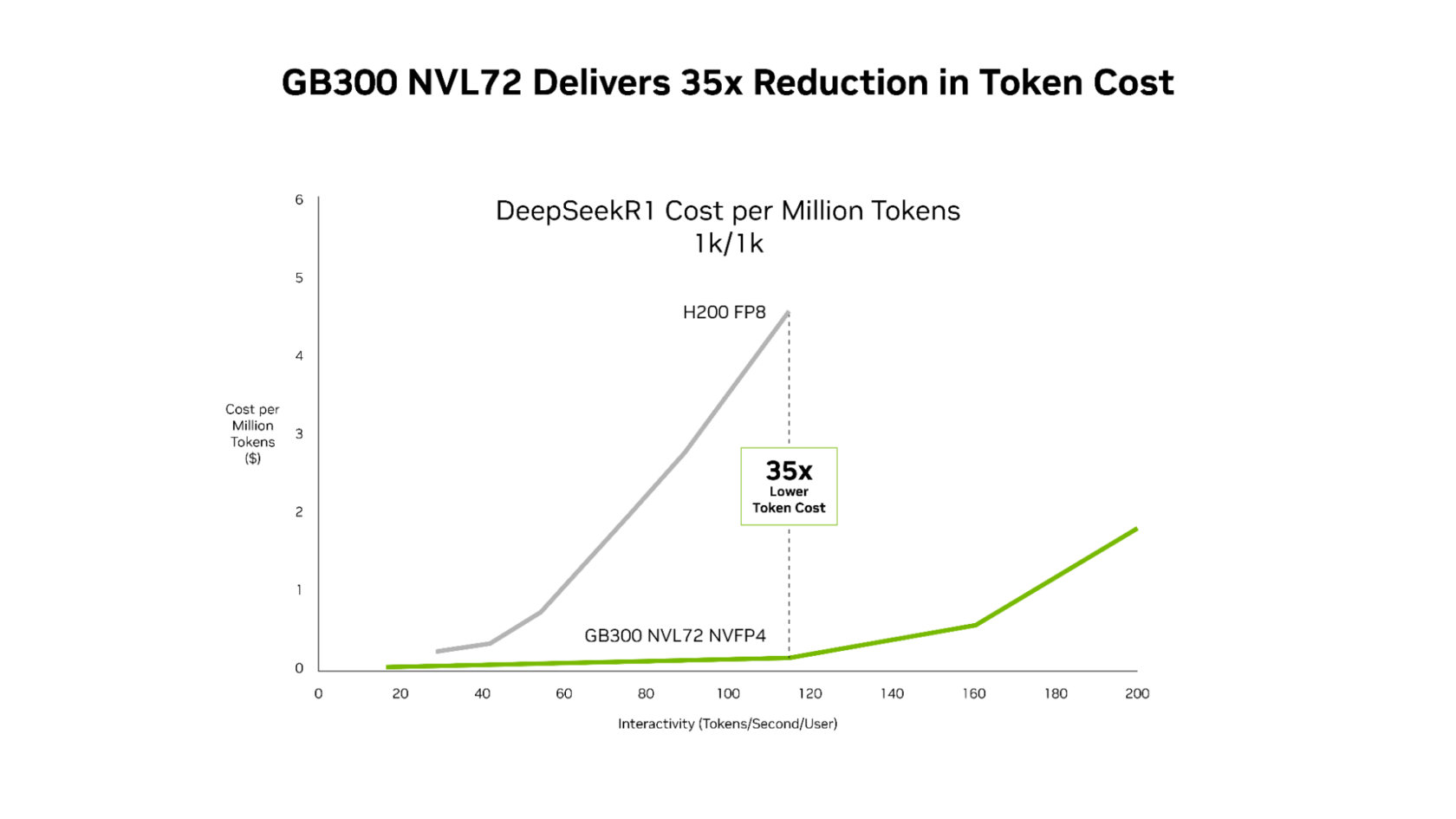
Bei agentischer Programmierung und interaktiven Assistenzanwendungen, bei denen jede Millisekunde in mehrstufigen Arbeitsabläufen entscheidend ist, ermöglicht diese Kombination aus konsequenter Softwareoptimierung und Hardware der nächsten Generation den KI-Plattformen, interaktive Echtzeit-Erlebnisse auf eine deutlich größere Nutzerzahl auszuweiten.
GB300 NVL72 bietet überragende Wirtschaftlichkeit für Workloads mit langem Kontext
Während sowohl GB200 NVL72 als auch GB300 NVL72 effizient eine extrem niedrige Latenz bieten, zeigen sich die klaren Vorteile von GB300 NVL72 am deutlichsten in Szenarien mit langen Kontexten. Für Workloads mit 128.000-Token-Eingaben und 8.000-Token-Ausgaben – wie KI-Programmierassistenten, die über Codebasen hinweg arbeiten – bietet GB300 NVL72 bis zu 1,5-mal geringere Kosten pro Token im Vergleich zu GB200 NVL72.
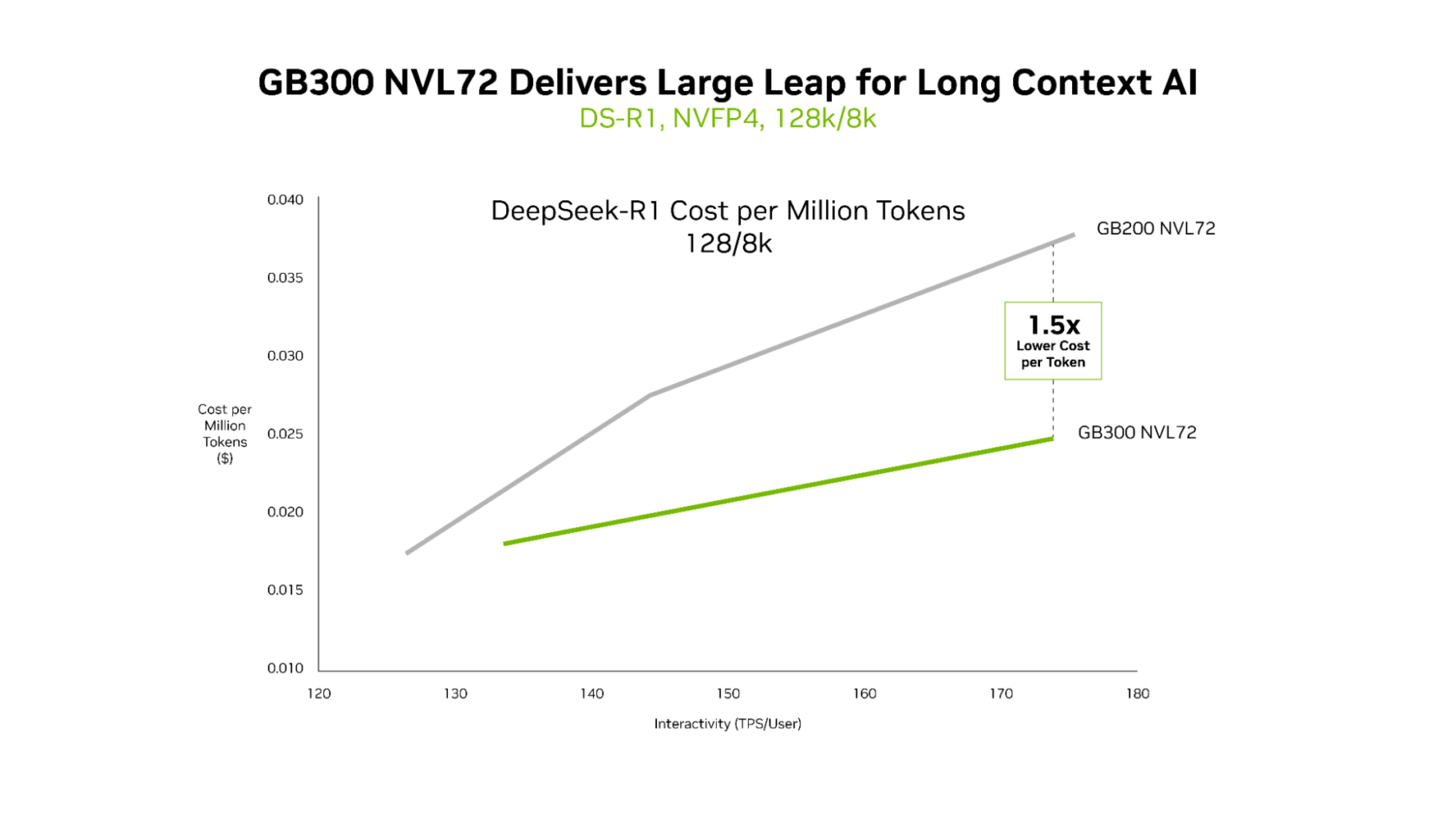
Der Kontext wächst, je mehr Code ein Agent einliest. Dadurch kann es die Codebasis besser verstehen, erfordert aber auch deutlich mehr Rechenleistung. Blackwell Ultra verfügt über eine 1,5-mal höhere NVFP4-Rechenleistung und 2-mal schnellere Aufmerksamkeitsverarbeitung, sodass der Agent ganze Codebasen effizient verstehen kann.
Infrastruktur für agentische KI
Führende Cloud-Anbieter und KI-Innovatoren nutzen NVIDIA GB200 NVL72 bereits in großem Maßstab und setzen GB300 NVL72 auch in der Produktion ein. Microsoft, CoreWeave und OCI setzen GB300 NVL72 für Anwendungsfälle mit geringer Latenz und langen Kontexten wie agentenbasierte Codierung und Codierungsassistenten ein. Durch die Reduzierung der Token-Kosten ermöglicht GB300 NVL72 eine neue Klasse von Anwendungen, die riesige Codebasen in Echtzeit analysieren können.
„Da Inferenz in den Mittelpunkt der KI-Produktion rückt, werden Performance in langen Kontexten und Token-Effizienz entscheidend“, erklärt Chen Goldberg, Senior Vice President of Engineering bei CoreWeave. „Grace Blackwell NVL72 geht diese Herausforderung direkt an, und die KI-Cloud von CoreWeave, einschließlich CKS und SUNK, ist darauf ausgelegt, die Vorteile der GB300-Systeme – aufbauend auf dem Erfolg des GB200 – in berechenbare Leistung und Kosteneffizienz umzusetzen.“ Das Ergebnis ist eine bessere Token-Ökonomie und eine für Kunden, die Workloads in großem Maßstab ausführen, besser nutzbare Inferenz.“
NVIDIA Vera Rubin NVL72 liefert Leistung der nächsten Generation
Mit dem großflächigen Einsatz von NVIDIA Blackwell Systemen werden durch kontinuierliche Softwareoptimierungen weitere Leistungssteigerungen und Kosteneinsparungen in der gesamten installierten Basis erzielt.
Künftig wird die NVIDIA Rubin Platform, die aus sieben neuen Chips einen KI-Supercomputer bildet – voraussichtlich eine weitere Runde massiver Leistungssprünge ermöglichen. Für MoE-Inferenz bietet sie einen bis zu 10-mal höheren Durchsatz pro Megawatt im Vergleich zu Blackwell, wodurch die Kosten pro Million Token auf ein Zehntel sinken. Für die nächste Generation von wegweisenden KI-Modellen kann Rubin große MoE-Modelle trainieren. Im Vergleich zu Blackwell wird dafür nur ein Viertel der Anzahl an GPUs benötigt.
Erfahren Sie mehr über die NVIDIA Rubin-Plattform und das Vera Rubin NVL72-System.