
Eine diagnostische Erkenntnis aus der Gesundheitsbranche. Der Dialog eines Charakters in einem interaktiven Spiel. Die autonome Lösung eines Kundendienstmitarbeiters. Jede dieser KI-gestützten Interaktionen basiert auf derselben intelligenten Einheit: einem Token
Um mehr dieser KI-Interaktionen auszuführen, müssen sich Unternehmen überlegen, ob sie sich mehr Token leisten können. Die Antwort liegt in besserer Tokenomics – bei der es im Wesentlichen darum geht, die Kosten pro Token zu senken. Dieser Abwärtstrend zeigt sich in allen Branchen. Jüngste Forschungsergebnisse des MIT zeigen, dass Infrastruktur- und algorithmische Effizienzsteigerungen die Inferenzkosten für Leistungen auf Spitzenniveau jährlich um bis zu das Zehnfache senken.
Um zu verstehen, wie die Effizienz der Infrastruktur die Tokenomics verbessert, kann man sich eine Hochgeschwindigkeitsdruckmaschine als Beispiel vor Augen führen. Wenn die Druckmaschine durch zusätzliche Investitionen in Druckfarbe, Energie und die Maschine selbst die zehnfache Leistung erbringt, sinken die Kosten für den Druck jeder einzelnen Seite. Ebenso können Investitionen in die KI-Infrastruktur im Vergleich zum Kostenanstieg zu einer weitaus höheren Token-Produktion führen – was eine deutliche Senkung der Kosten pro Token zur Folge hat.
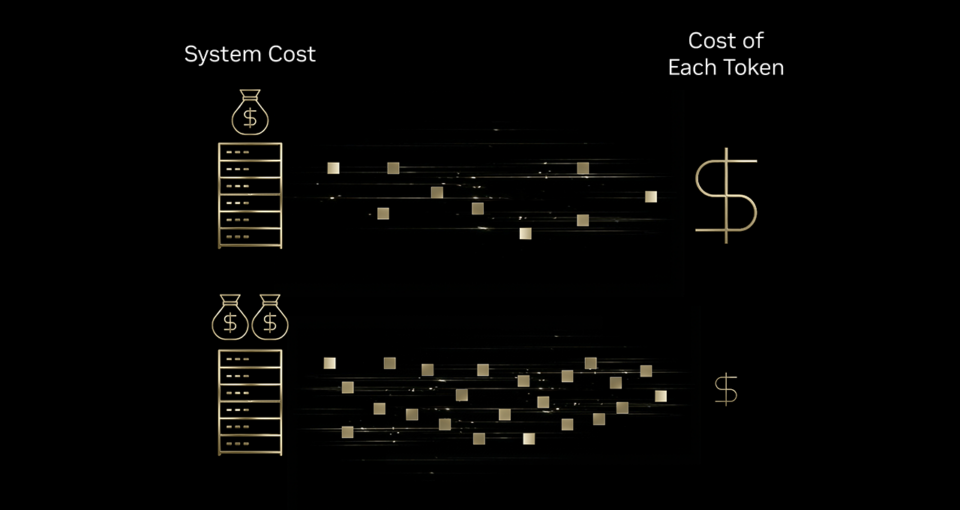
Aus diesem Grund nutzen führende Inferenzanbieter wie Baseten, DeepInfra, Fireworks AI und Together AI die NVIDIA Blackwell-Plattform, die ihnen hilft, die Kosten pro Token um das bis zu 10-Fache im Vergleich zur NVIDIA Hopper-Plattform zu senken.
Diese Anbieter hosten fortschrittliche Open-Source-Modelle, die mittlerweile ein Spitzenniveau an Intelligenz erreicht haben. Durch die Kombination von Open-Source-Frontier-Intelligence, dem innovativen Hardware-Software-Co-Design von NVIDIA Blackwell und ihren eigenen optimierten Inferenz-Stacks ermöglichen diese Anbieter Unternehmen aller Branchen eine drastische Senkung der Token-Kosten.
Gesundheitswesen – Baseten und Sully.ai reduzieren die KI-Inferenzkosten um das Zehnfache
Im Gesundheitswesen schränken mühsame, zeitaufwändige Aufgaben wie die medizinische Kodierung, die Dokumentation und die Bearbeitung von Versicherungsformularen die Zeit ein, die Ärzte mit ihren Patienten verbringen können.
Sully.ai hilft, dieses Problem mit „KI-Mitarbeitern“ zu lösen, die Routineaufgaben wie medizinische Kodierung und das Anfertigen von Notizen übernehmen. Mit dem Wachstum der Unternehmensplattform führten die proprietären Closed-Source-Modelle zu drei Engpässen: unvorhersehbare Latenzzeiten in klinischen Echtzeit-Arbeitsabläufen, Inferenzkosten, die schneller stiegen als die Einnahmen, sowie unzureichende Kontrolle über die Qualität und Updates der Modelle.
Um diese Engpässe zu überwinden, nutzt Sully.ai die Modell-API von Baseten, die Open-Source-Modelle wie gpt-oss-120b auf NVIDIA Blackwell GPUs bereitstellt. Baseten nutzte das NVFP4-Datenformat mit geringer Genauigkeit, die NVIDIA TensorRT-LLM-Bibliothek und das NVIDIA Dynamo Inferenz-Framework, um optimierte Inferenz bereitzustellen. Das Unternehmen entschied sich für NVIDIA Blackwell für die Ausführung seiner Modell-API, nachdem damit ein bis zu 2,5-mal besserer Durchsatz pro Dollar im Vergleich zu NVIDIA Hopper erzielt werden konnte.
In der Folge fielen die Inferenzkosten von Sully.ai um 90 %. Dies entspricht einer Reduzierung um das Zehnfache im Vergleich zur vorherigen proprietären Implementierung, während sich die Reaktionszeiten um 65 % verbesserten, insbesondere bei kritischen Workflows wie der Erstellung medizinischer Aufzeichnungen. Das Unternehmen hat Ärzten inzwischen über 30 Millionen Minuten zurückgegeben, Zeit, die zuvor durch die Dateneingabe und andere manuelle Aufgaben verloren gingen.
Gaming — DeepInfra und Latitude reduzieren die Kosten pro Token um 75 %
Latitude entwickelt die Zukunft des KI-nativen Gamings mit dem Abenteuerspiel AI Dungeon und der angekündigten KI-gestützten Rollenspiel-Plattform Voyage, auf der Spieler jede Aktion frei wählen und ihre eigene Geschichte erzählen können, während sie Welten erstellen oder erkunden.
Die Plattform des Unternehmens nutzt große Sprachmodelle, um auf die Aktionen der Spieler zu reagieren. Dies bringt jedoch Herausforderungen bei der Skalierung mit sich, da jede Aktion der Spieler eine Inferenzanfrage auslöst. Die Kosten steigen mit dem Engagement, und die Reaktionszeiten müssen kurz genug bleiben, um ein nahtloses Erlebnis zu gewährleisten.

Latitude führt große Open-Source-Modelle auf der Inferenzplattform von DeepInfra aus, die von NVIDIA Blackwell GPUs und TensorRT LLM betrieben wird. Für ein großes Mixture-of-Experts-Modell (MoE) konnte DeepInfra die Kosten pro eine Million Token von 20 Cent mit NVIDIA Hopper auf 10 Cent mit Blackwell senken. Durch den Wechsel zum nativen NVFP4-Format von Blackwell mit geringer Genauigkeit sanken die Kosten weiter auf nur noch 5 Cent – eine 4-fache Reduzierung der Kosten pro Token – bei gleichzeitiger Aufrechterhaltung der von den Kunden erwarteten Genauigkeit.
Durch die Ausführung dieser großen MoE-Modelle auf der Blackwell-basierten Plattform von DeepInfra liefert Latitude auf kostengünstige Weise schnelle, zuverlässige Antworten. Die Inferenzplattform von DeepInfra bietet diese Leistung und bewältigt gleichzeitig Traffic-Spitzen zuverlässig, sodass Latitude leistungsfähigere Modelle einsetzen kann, ohne dass das Spielerlebnis beeinträchtigt wird.
Agentischer Chat – Fireworks AI und Sentient Foundation senken die KI-Kosten um bis zu 50 %
Sentient Labs konzentriert sich darauf, KI-Entwickler zusammenzubringen, um leistungsstarke KI-Systeme mit Fähigkeiten zur logischen Schlussfolgerung zu entwickeln, die alle auf Open-Source basieren. Das Ziel ist es, die KI zur Lösung schwieriger Reasoning-Probleme durch Forschung in den Bereichen sichere Autonomie, agentische Architektur und kontinuierliches Lernen zu beschleunigen.
Die erste App, Sentient Chat, orchestriert komplexe Multi-Agenten-Workflows und integriert mehr als ein Dutzend spezialisierter KI-Agenten aus der Community. Aus diesem Grund hat Sentient Chat einen enorm hohen Rechenbedarf, da eine einzelne Benutzeranfrage eine Kaskade autonomer Interaktionen auslösen kann, die in der Regel zu kostspieligem Infrastruktur-Overhead führen.
Um diese Größenordnung und Komplexität zu bewältigen, nutzt Sentient die Inferenzplattform von Fireworks AI, die auf NVIDIA Blackwell arbeitet. Mit dem durch Blackwell optimierten Inferenz-Stack von Fireworks erzielte Sentient eine 25-50 % bessere Kosteneffizienz im Vergleich zu der vorherigen auf Hopper basierten Bereitstellung.
Dieser höhere Durchsatz pro GPU ermöglichte es dem Unternehmen, deutlich mehr gleichzeitige Nutzer zu gleichen Kosten zu bedienen. Die Skalierbarkeit der Plattform unterstützte eine virale Einführung von 1,8 Millionen Benutzern der Warteliste in 24 Stunden und verarbeitete 5,6 Millionen Anfragen in einer einzigen Woche, während gleichzeitig eine konsistente geringe Latenz gewährleistet wurde.
Kundenservice – Together AI und Decagon senken die Kosten um das 6-Fache
Kundenservice-Anrufe mit Sprach-KI enden häufig in Frustration, da selbst eine geringfügige Verzögerung dazu führen kann, dass Benutzer den Agenten unterbrechen, auflegen oder das Vertrauen verlieren.
Decagon entwickelt KI-Agenten für den Kundensupport von Unternehmen. KI-gestützte Sprachunterstützung ist dabei der anspruchsvollste Kanal. Decagon benötigte eine Infrastruktur, die auch bei unvorhersehbarer hoher Auslastung Reaktionszeiten von unter einer Sekunde gewährleisten konnte und eine Tokenomics bot, die den Sprachbetrieb rund um die Uhr gewährleistete.

Together AI führt die Produktionsinferenz für den Multimodel-Voice-Stack von Decagon auf NVIDIA Blackwell GPUs aus. Die Unternehmen arbeiteten bei mehreren wichtigen Optimierungen zusammen: spekulatives Dekodieren, bei dem kleinere Modelle trainiert werden, um schnellere Antworten zu generieren, während ein größeres Modell im Hintergrund die Genauigkeit überprüft, das Zwischenspeichern wiederkehrender Konversationselemente zur Beschleunigung der Antworten sowie die Entwicklung einer automatischen Skalierung, die Traffic-Spitzen bewältigt, ohne die Leistung zu beeinträchtigen.
Decagon erzielte Reaktionszeiten von unter 400 Millisekunden, selbst bei der Verarbeitung von Tausenden von Token pro Abfrage. Die Kosten pro Abfrage, d. h. die Gesamtkosten für die Fertigstellung einer Sprachinteraktion, wurden um das 6-Fache gesenkt im Vergleich zur Verwendung proprietärer Closed-Source-Modelle. Dies wurde durch die Kombination des Multimodel-Ansatzes von Decagon (davon einige Open Source, andere intern auf NVIDIA GPUs trainiert), dem extremen Codesign von NVIDIA Blackwell und dem optimierten Inferenz-Stack von Together erreicht.
Optimierte Tokenomics mit extremem Co-Design
Die erheblichen Kosteneinsparungen im Gesundheitswesen, in den Bereichen Gaming und im Kundenservice werden durch die Effizienz von NVIDIA Blackwell ermöglicht. Das NVIDIA GB200 NVL72 System steigert diese Wirkung noch weiter, indem es im Vergleich zu NVIDIA Hopper eine bahnbrechende 10-fache Senkung der Kosten pro Token für die Inferenz von MoE-Modellen ermöglicht.
Das extreme Co-Design von NVIDIA, das alle Ebenen des Stacks umfasst – von Rechenleistung über Netzwerke bis hin zu Software – sowie das Partner-Ökosystem des Unternehmens ermöglichen eine drastische Senkung der Kosten pro Token im großen Maßstab.
Diese Dynamik setzt sich mit der NVIDIA Rubin-Plattform fort, bei der sieben neue Chips in einen einzigen KI-Supercomputer integriert werden, um 10-mal mehr Leistung und 10-mal geringere Token-Kosten im Vergleich zu Blackwell zu bieten.
Entdecken Sie die Full-Stack-Inferenzplattform von NVIDIA, und melden Sie sich für die NVIDIA GTC 2026-Sitzungen zu Tokenomics für KI-Inferenz an, um mehr darüber zu erfahren, wie diese Plattform eine verbesserte Tokenomics für KI-Inferenz ermöglicht.