
Im Bereich der KI für Unternehmen ist das Verstehen und Arbeiten in mehreren Sprachen nicht mehr optional, sondern unerlässlich, um die Anforderungen von Mitarbeitern, Kunden und Benutzern weltweit zu erfüllen.
Mehrsprachiges Abrufen von Informationen – die Fähigkeit, Wissen in verschiedenen Sprachen zu suchen, zu verarbeiten und abzurufen – spielt eine wesentliche Rolle hinsichtlich der KI und wie sie präzisere und global relevante Ausgaben bereitstellt.
Unternehmen können ihre generativen KI-Bemühungen um präzise mehrsprachige Systeme ausweiten, indem sie NVIDIA NIM Microservices mit NVIDIA NeMo Retriever einbetten und neu klassifizieren lassen. Die NIM Microservices sind jetzt im NVIDIA API-Katalog verfügbar. Diese Modelle können Informationen in einer Vielzahl von Sprachen und Formaten verstehen, z. B. als Dokumente, um präzise, kontextorientierte Ergebnisse in großem Umfang bereitzustellen.
Mit NeMo Retriever können Unternehmen jetzt:
- Wissen aus großen und vielfältigen Datenmengen extrahieren, um zusätzlichen Kontext zu erhalten und genauere Antworten bereitzustellen.
- generative KI nahtlos mit Unternehmensdaten in den meisten wichtigen Sprachen der Welt verbinden und so das Benutzerpublikum erweitern.
- umsetzbare Informationen in größerem Umfang bereitstellen mit einer 35-fach verbesserten Datenspeichereffizienz durch neue Techniken wie Long Context Support und Dynamic Embedding Sizing.
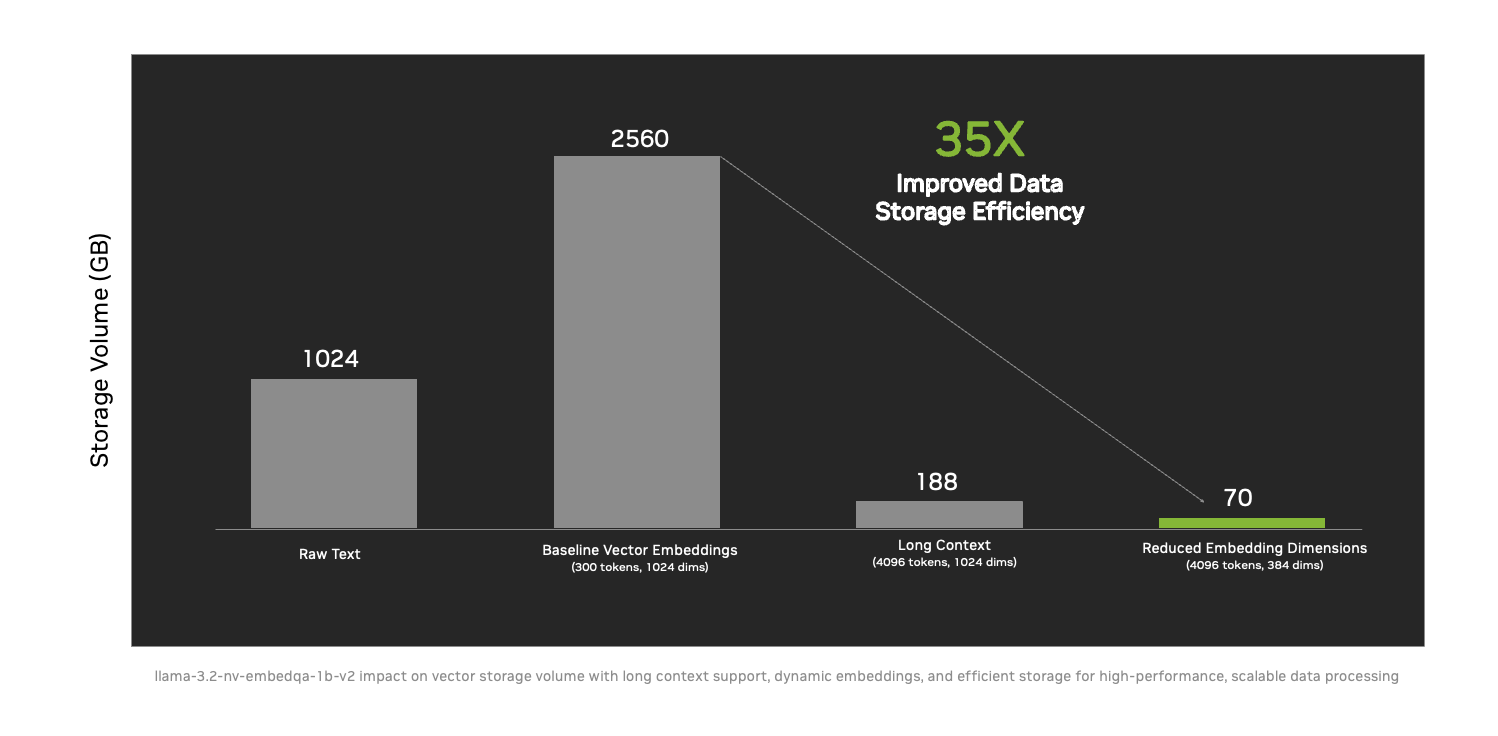 Die neuen NeMo Retriever Microservices reduzieren den Bedarf an Datenspeichervolumen um das 35-fache, sodass Unternehmen mehr Informationen auf einmal verarbeiten und große Wissensdatenbanken auf einem einzigen Server unterbringen können. Dadurch werden KI-Lösungen zugänglicher, kostengünstiger und können leichter in Unternehmen skaliert werden.
Die neuen NeMo Retriever Microservices reduzieren den Bedarf an Datenspeichervolumen um das 35-fache, sodass Unternehmen mehr Informationen auf einmal verarbeiten und große Wissensdatenbanken auf einem einzigen Server unterbringen können. Dadurch werden KI-Lösungen zugänglicher, kostengünstiger und können leichter in Unternehmen skaliert werden.
Führende NVIDIA Partner wie DataStax, Cohesity, Cloudera, Nutanix, SAP, VAST Data und WEKA setzen diese Microservices bereits ein, um Unternehmen aus allen Branchen zu helfen, eigene Modelle auf sichere Weise mit vielfältigen und großen Datenquellen zu verbinden. Durch den Einsatz von Retrieval-Augmented Generation (RAG)-Techniken ermöglicht NeMo Retriever KI-Systemen den Zugriff auf reichhaltigere und relevantere Informationen, was die Überbrückung sprachlicher und kontextueller Trennlinien zulässt.
Wikidata beschleunigt die Datenverarbeitung von 30 Tagen auf weniger als drei Tage
Wikimedia hat in Zusammenarbeit mit DataStax NeMo Retriever implementiert, um Wikipedia-Inhalte als Vektoren einzubetten und somit Milliarden von Benutzern zu versorgen. Vektoreinbettung oder „Vektorisierung“ ist ein Prozess, der Daten in ein Format umwandelt, das KI verarbeiten und verstehen kann, um Erkenntnisse zu extrahieren und intelligente Entscheidungen zu treffen.
Wikimedia nutzte NeMo Retriever für die Einbettung und Neuklassifizierung von NIM Microservices, um über 10 Millionen Wikidata-Einträge in weniger als drei Tagen in KI-bereite Formate zu vektorisieren. Ein Prozess, der früher 30 Tage in Anspruch nahm. Diese 10-fache Beschleunigung ermöglicht einen skalierbaren, mehrsprachigen Zugriff auf einen der größten Open-Source-Wissensgraphen der Welt.
Dieses bahnbrechende Projekt sorgt für Echtzeit-Aktualisierungen Hunderttausender Einträge, die täglich von Tausenden von Mitwirkenden bearbeitet werden, was den globalen Zugang für Entwickler und Benutzer gleichermaßen verbessert. Mit dem serverlosen Modell von Astra DB und den NVIDIA AI Techniken bietet das Angebot von DataStax eine Latenz von nahezu null und außergewöhnliche Skalierbarkeit zur Unterstützung der dynamischen Anforderungen der Wikimedia-Community.
DataStax nutzt NVIDIA AI Blueprints und integriert die Microservices NVIDIA NeMo Customizer, Curator, Evaluator und Guardrails in den LangFlow KI-Code-Builder, um es dem Entwicklerumfeld zu ermöglichen, KI-Modelle und Pipelines für ihre einzigartigen Anwendungsfälle zu optimieren und Unternehmen zu helfen, ihre KI-Anwendungen zu skalieren.
Sprachinklusive KI bringt geschäftliche Auswirkungen weltweit voran
NeMo Retriever unterstützt globale Unternehmen dabei, sprachliche und kontextuelle Barrieren zu überwinden und das Potenzial ihrer Daten zu erschließen. Durch den Einsatz robuster KI-Lösungen können Unternehmen präzise, skalierbare und äußerst wirkungsvolle Ergebnisse erzielen.
Die Plattform- und Beratungspartner von NVIDIA spielen eine entscheidende Rolle hinsichtlich der Sicherstellung einer effizienten Einführung und Integration generativer KI-Funktionen durch Unternehmen, wie z. B. die neuen mehrsprachigen NeMo Retriever Microservices. Diese Partner helfen dabei, KI-Lösungen an die einzigartigen Anforderungen und Ressourcen eines Unternehmens anzupassen und generative KI so zugänglicher und effektiver zu machen. Zu den Partnern gehören:
- Cloudera plant, die Integration von NVIDIA AI auf den Cloudera AI Inference Service auszuweiten. Cloudera AI Inference ist derzeit in NVIDIA NIM eingebettet und wird um NVIDIA NeMo Retriever erweitert, um die Geschwindigkeit und Qualität von Erkenntnissen für mehrsprachige Anwendungsfälle zu verbessern.
- Cohesity hat den ersten auf generativer KI basierenden konversationellen Suchassistenten der Branche eingeführt, der Backup-Daten nutzt, um aufschlussreiche Antworten bereitzustellen. Der Assistent nutzt den NVIDIA NeMo Retriever Microservice für die Neuklassifizierung zur Verbesserung der Abrufgenauigkeit sowie zur deutlichen Steigerung der Geschwindigkeit und Qualität von Erkenntnissen für verschiedene Anwendungen.
- SAP nutzt die Grounding-Funktionen von NeMo Retriever, um seiner Joule-Copilot-F&A-Funktion sowie Informationen aus benutzerdefinierten Dokumenten Kontext zu verleihen.
- VAST Data setzt NeMo Retriever Microservices auf der VAST Data InsightEngine mit NVIDIA ein, um neue Daten sofort für die Analyse verfügbar zu machen. Dies beschleunigt die Erkennung von Geschäftserkenntnissen, indem Echtzeitinformationen für KI-gestützte Entscheidungen erfasst und organisiert werden.
- WEKA integriert seine WEKA AI RAG Reference Platform (WARRP)-Architektur mit NVIDIA NIM und NeMo Retriever in seine Datenplattform mit geringer Latenz, um skalierbare, multimodale KI-Lösungen bereitzustellen, die Hunderttausende von Token pro Sekunde verarbeiten.
Überwindung von Sprachbarrieren mit mehrsprachiger Informationsabfrage
Das mehrsprachige Abrufen von Informationen ist für KI der Unternehmensklasse unerlässlich, um reale Anforderungen zu erfüllen. NeMo Retriever unterstützt das effiziente und genaue Abrufen von Texten in mehreren Sprachen und sprachübergreifenden Datenmengen. Es wurde für Anwendungsfälle in Unternehmen wie Suchfunktionen, die Beantwortung von Fragen, Zusammenfassungen und Empfehlungssysteme entwickelt.
Darüber hinaus wird damit eine äußerst wichtige Herausforderung im Bereich Enterprise-KI gelöst – die Verarbeitung großer Mengen großer Dokumente. Mithilfe von Long-Context Support können die neuen Microservices langwierige Verträge und detaillierte Patientenakten verarbeiten und dabei die Genauigkeit und Konsistenz über längere Interaktionen hinweg beibehalten.
Diese Funktionen helfen Unternehmen dabei, ihre Daten effektiver zu nutzen und präzise, zuverlässige Ergebnisse für Mitarbeiter, Kunden und Benutzer bereitzustellen sowie Ressourcen für die Skalierbarkeit zu optimieren. Fortschrittliche mehrsprachige Abfrage-Tools wie NeMo Retriever machen KI-Systeme in einer globalisierten Welt anpassungsfähiger, zugänglicher und wirkungsvoller.
Verfügbarkeit
Entwickler können über den NVIDIA API-Katalog oder eine kostenlose, 90-tägige NVIDIA AI Enterprise Entwicklerlizenz auf die mehrsprachigen NeMo Retriever Microservices und andere NIM Microservices zugreifen, um Informationen abzurufen.
Erfahren Sie mehr über die neuen NeMo Retriever Microservices und wie Sie sie zur Entwicklung effizienter Informationsabrufsysteme nutzen können.